
Full-Stack Go App with HTMX and Alpine.js
Can you create an application that feels like it was built with React or Vue without ever leaving Go code? Almost. You'll still need a touch of JavaScript, but much less than you might expect. Read on to find out how.
I’ve pondered this for quite some time. I searched extensively for a frontend-like framework built with Go, but every one I tried was either too complex, overly opinionated, or poorly maintained. For me, this idea always seemed to belong to the realm of dreams.
I’ve never been particularly fond of frontend frameworks because they each have their own unique way of doing things. In my experience, that makes refactoring inevitable. To be honest, most of the JavaScript ecosystem feels overly opinionated to me. The language lacks a robust standard library, and NPM packages, indispensable parts I may say, frequently change their syntax or simply disappear. It’s as if JavaScript code is perpetually in a state of flux.
Don’t get me wrong — I’m not anti-JavaScript. I’m not against any technology. You can’t be upset with a hammer because it can’t drive a screw. JavaScript is a necessity; building web interfaces without it is challenging. Sure, you can use Blazor, Phoenix LiveView, and similar frameworks, but they are based on languages and concepts with a steeper learning curve, which can be daunting for developers who are not already familiar with their nuances.
Last year, we had to migrate a Vue2 application to Vue3 at Infinite, and oh boy, what a nightmare that was. I decided then that I never wanted to go through such a process again and waste so much money. So, I began searching for a hybrid approach.
Something that harnessed JavaScript’s raw power without demanding a piece of my soul every few months. Something that allowed me to write mostly vanilla JavaScript and, if changes were necessary, wouldn’t require months of refactoring. To my surprise, such a solution existed — actually, two.
Live Long and JS Light 🖖
Thanks to a chap from Bozeman, Montana — no, not Zefram Cochrane, but a professor named Carson Gross — we have HTMX, an anti-JavaScript framework built with JavaScript that secured second place among frontend frameworks at the 2023 JavaScript Rising Starts. Wait, what?
As paradoxical as it sounds, you read that right. This JavaScript framework, whose marketing strategy is 99% meme-based on Twitter, was designed to let you leverage modern browser features directly from HTML.

Consider the following code:
<button
hx-post="/clicked"
hx-trigger="click"
hx-target="#parent-div"
hx-swap="outerHTML"
>
Click Me!
</button>This tells HTMX:
“When a user clicks on this button, issue an HTTP POST request to ‘/clicked’ and use the content from the response to replace the element with the id
parent-divin the DOM.”
It’s radically different from React, Vue, and Angular, yet refreshingly simple (ba dum tss). I won't delve further into HTMX because their documentation is quite comprehensive. Give it a go — I'm sure you'll be pleasantly surprised.
I mentioned two solutions, right? The other mature library that is quite similar to HTMX is called Unpoly. Unpoly is quite interesting. It’s actually even a bit more complete than HTMX. They foresaw back in 2015 that separating the frontend entirely from the backend would double the complexity.

I tried Unpoly and was impressed. It even includes a layer API that lets you create modals and maintain the browser's history seamlessly. However, for what I was aiming for, Unpoly didn't meet my expectations — more on that later.
Let’s move on to the architecture of the promised full-stack Go application with minimal JavaScript required.
The Mayans' Way
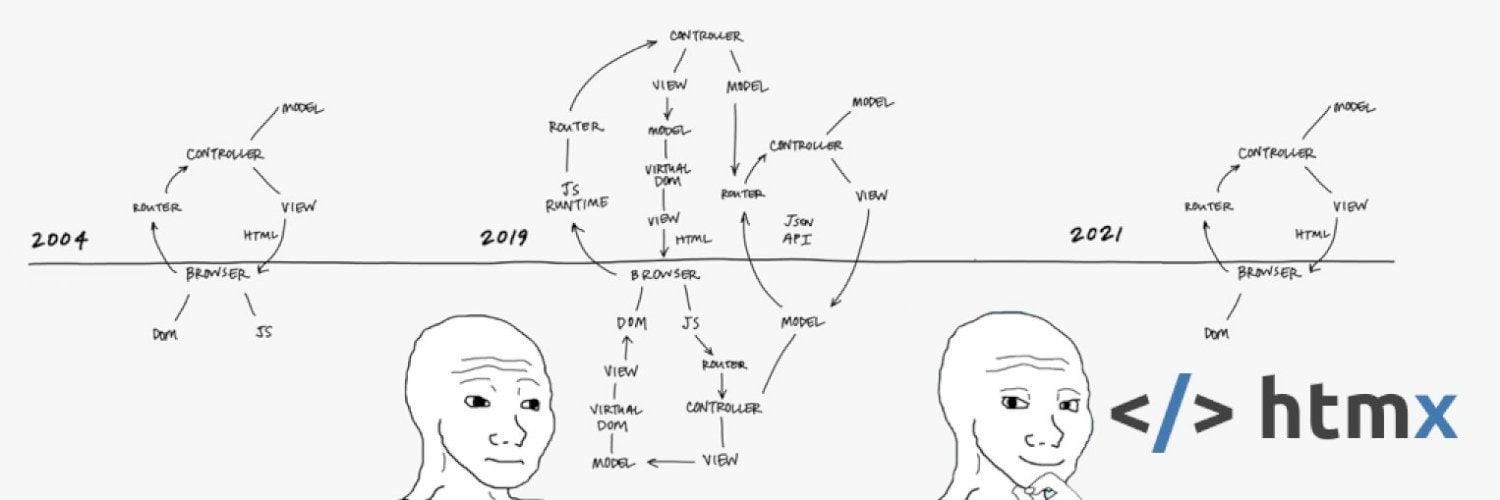
Before React and its gang took the throne, applications were full-stack. The backend rendered HTML with information directly from the database. There was no JSON to ingest via API and transform into HTML via JSX.
This didn’t allow for the single-page application experience we are accustomed to today. Even the slightest change on the page triggered a full page reload. We had "some" animations with jQuery’s help, but it was nothing compared to what we’re used to now.
Most developers back then were full-stack. In fact, I don’t recall ever hearing the term "frontend engineer". We were just, well, developers.
Was the code simpler? That largely depended on how much the developer cared about readability and maintainability, but in a way, code lasted longer, and we had fewer concepts to learn.
If we compare this to applications requiring server-side rendering (SSR), which nowadays necessitates an intermediary framework with its unique concepts, then yes, the code back then in this situation was logarithmically simpler.
The most popular architectural pattern back then was MVC. Oversimplified, it separated the frontend (the V for view) from the backend logic (MC for model and controllers). Honestly, it wasn’t the best architecture; your code was still highly coupled with your infrastructure, and controllers often became bloated. Sometimes, the entire business logic was in the database. Yeah, insane, right?
Over time, we’ve learned what works in the long term and what doesn’t. We understand the kind of client-side reactivity we need, and we can use Clean Architecture to better organize our code. So why not go for a hybrid approach?
The Hybrid Approach
Starting with the client side, certain complexities are unavoidable. Off the top of my head, I can think of state management, asynchronous behaviors, and dynamic updates.
HTMX provides dynamic updates, including polling. We can listen to events and trigger updates on the page. In fact, you can even parse JSON responses with it. However, we need something to manage state and trigger updates based on that state.
Enter Alpine.js — a minimal, super lightweight JavaScript framework inspired by Vue's syntax but requiring no build steps or virtual DOM. It’s pretty much plug-and-play.
Alpine allows us to store state locally, globally, and even persistently. We can also trigger actions on the page based on state changes, filling in the last missing part of our client-side equation.

There is also a similar framework called Hyperscript, made by the same authors as HTMX, but its syntax is quite different from what you might be used to. I tried it in a couple of scenarios during the PoC development, and the Alpine code was much easier to understand and less likely to require a refactor when if the syntax changes.
From this point, we delve into the code used in the proof of concept repository. You are welcome to explore the full codebase, fork it, or even run the binary available on the Releases page if you're interested.
Let’s take a look at the first code snippet of this article — a component to display a "Toast", that message that usually appears at the bottom right of the page when an action is performed.
If you have any experience with JavaScript, the code should be pretty self-explanatory. The amusing thing is, this is the most complicated part of the frontend code.
It listens to JavaScript events and triggers the display of the "Toast" message when needed. The rest of the code is plain HTML with a few Alpine tags to show or hide parts of the code depending on the state.
You may have noticed that the "Toast" is going to be displayed every time a request of type application/json is made. Wait, JSON? What?
Yes. I'm showing this code not only because it's the most complicated part of the code and you can still understand it without much explanation, but also to give you a clue about how I structure the application.
Most developers using HTMX create endpoints that return fragments of the HTML page in response to API calls. However, returning such fragments would require me to split the HTML of my pages into templates and essentially have a duplicated REST API — one for JSON and another for HTML.
"Aah, but you can use middleware to convert the output." Sure, but your APIs will eventually diverge significantly, with some endpoints only useful for HTML pages and others only for JSON.
Instead, how about having the UI layer return only full HTML pages? Allow components to self-update based on events and perform write operations via a REST API. Sounds complex? Let’s explore these ideas further.
Self-Updating Components
Take a look at the main page. It features a table listing all the Contacts entities and a form for creating new contacts. Focus on the table part:
<table
id="contacts-table"
hx-get="/"
hx-trigger="submit from:form delay:500ms, click from:button.delete-contact delay:500ms"
hx-select="#contacts-table"
hx-target="#contacts-table"
hx-swap="outerHTML transition:true"
class="[...]"
>When a submit event from the form or a click event from the delete button occurs — both native JavaScript events — the table will automatically update. It will request the current page, select itself from the HTML, and replace itself.
That's why I didn't go for Unpoly. A self-updating component with Unpoly requires custom JavaScript code to be run, whereas with HTMX it's just a couple of tags in the HTML.
The create and update forms interact directly with the REST API. For instance:
<form
hx-post="/api/v1/contact/"
hx-indicator="#loading-overlay"
hx-swap="none"
hx-on::after-request="this.reset()"
>If an error occurs, HTMX developers typically hide an error div or return the error div via HTML fragments. But remember the "Toast" component we discussed? The output of the JSON requests will be displayed by it:
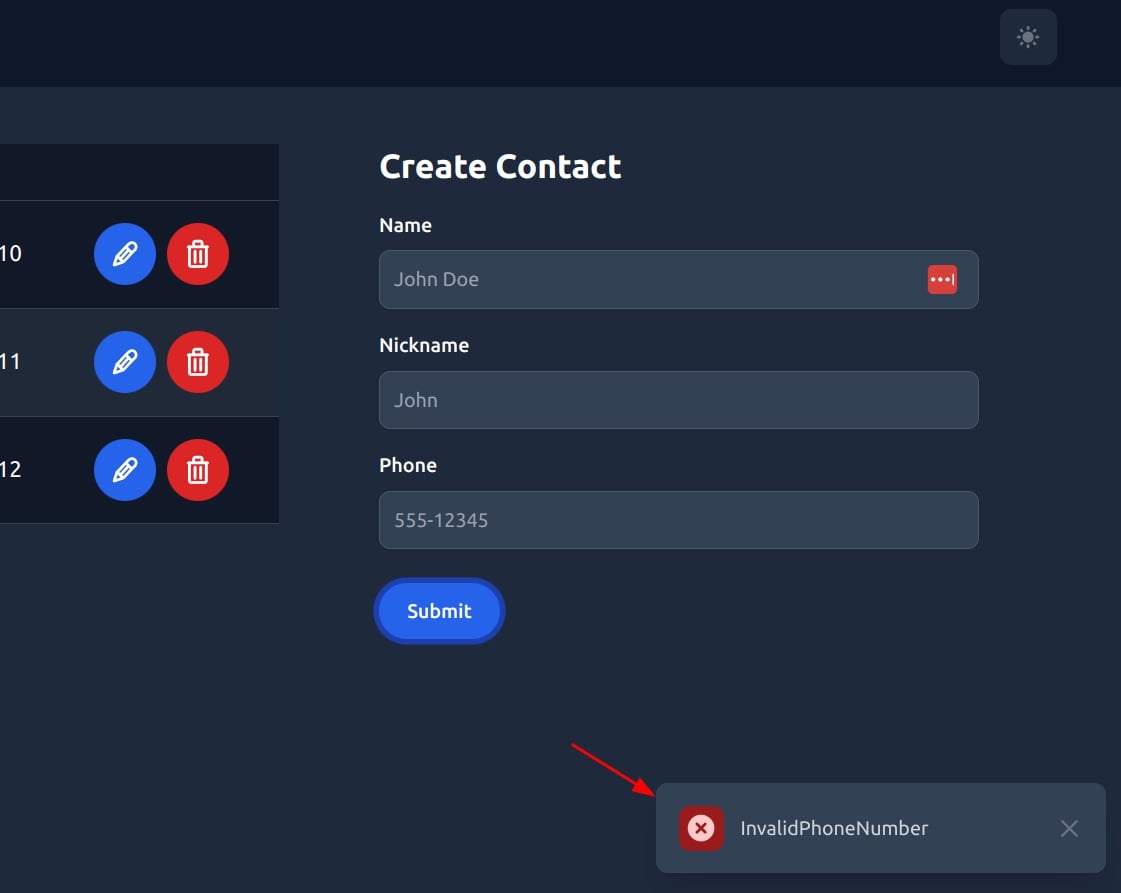
This way, most of my UI consists of pure HTML pages styled with TailwindCSS and very little JavaScript. I don't need to intercept the REST API requests at every endpoint because the "Toast" component already handles this, and the components on the page update themselves.
The only JavaScript part I haven’t explained yet, which you might have noticed on the main page, is that when the "update button" is clicked, the row value of the table is copied to the Alpine state so the "update modal" is auto-filled with the necessary data. Nothing new though, this is something you’re probably already used to with SPA frameworks:
<button
type="button"
@click={ "openUpdateModal(" + contact.JsonSerialize() + ")" }
class="[...]"
>As you can see, this new approach still requires some JavaScript. However, most of it is copy-and-paste and nearly unavoidable if, like me, you don’t want to return HTML fragments. It’s a healthy dose, I would say.
The template engine used in this code is a-h/templ, though there isn't much to elaborate on. It allows me to work with Go native and custom types and access properties such as the JsonSerialize() mentioned above, which is quite handy.
The UI layer is structured in a familiar SPA configuration, with the "presenters" consuming the same "read" services that the API and CLI use. If some of the data needed for a page takes a long time to fetch, I would recommend using HTMX load polling or consuming the API via JavaScript and using Alpine to render the HTML structure with x-for.
The Backstage Beauty
So far, we’ve primarily focused on the frontend aspects of this full-stack application. However, this project is actually the new version of the Clean Architecture with DDD proof of concept I wrote four years ago in PHP.
Let's call the non-UI part of the app "backstage", as the separation between backend and frontend is no longer black and white.
The Language
Previously, the proof of concept was written in PHP. This time, it was written in Go, which means the code is compiled into a single binary with no dependencies, capable of running on any platform.
There’s a bit of a debate between Rust, Zig, and Go developers, so let’s address that. I've experimented with Rust and Zig, as I’ve been writing so much infrastructure code that interpreted languages didn't fit the bill anymore. These are great languages, but compared to Go, they seem to offer finer granularity in exchange for a more "bureaucratic" developer experience.

I’ve had no problems with garbage collectors so far, perhaps because I'm not working on a platform with a billion monthly active users, nor am I working on embedded systems trying to extract the most out of the hardware. Go is easy to teach, has a great standard library, a good enough ecosystem, and plenty of documentation. The compile time is quite fast, and the final binary is sufficiently lightweight.
I'm sure there are many valid reasons why someone might choose Rust or Zig over Go depending on the use case, but for my small development team and me, Go has been such a great tool that we have very little to complain about.
The Service Layer
Web developers spend most of their time creating APIs and frontends. However, sometimes it's necessary to have an additional entry point such as a CLI. To avoid repeating the code in such situations, some developers make the CLI just a wrapper around the HTTP entry points, such as the Docker CLI.
In the projects I work on, I wasn't so fortunate to have a daemon running all the time so my CLI couldn't be just an HTTP wrapper. Some of the CLI endpoints I need to create may work partially or entirely different from the API.
To structure the "backstage" in a way that is humanly possible to understand and maintain, let's use Clean Architecture and DDD to our advantage. If you're not familiar with these concepts, I wrote a series of articles explaining them:
- Introduction to Clean Architecture & Domain-Driven Design on PHP
- The Domain Layer - Clean Architecture & Domain-Driven Design on PHP
- The Presentation Layer - Clean Architecture & Domain-Driven Design on PHP
Besides the common CA and DDD layers, you'll see that in this proof of concept there is a Service layer inside the presentation layer. This is not a useful layer if your application is a REST API only, but since there are three entry points now (REST API, CLI, and UI), some parts of the code would repeat themselves.

The service layer strategy is simple: all the data entering is mapped into a generic map[string]string by the controllers and inside the service layer, the raw data is converted and validated with the help of ValueObjects. From there, the service initiates the infrastructure implementations and injects the dependencies into the UseCases.
Thanks to the service layer addition, the code has no intentional panics/exceptions. I've finally made peace with err != nil and found a way to organize the code that is readable and less "boilerplate-y".
Models with Pre-Seed
The previous proof of concept stored the contact information as files. This time around, I'm using SQLite for the job. In production, you would likely not use SQLite unless you're using Turso, which I'm curious to see if it can really handle heavy loads, but the code shouldn't change much if you were to use MySQL or PostgreSQL, I suspect.
I thought that seeding a database should be a standard feature in ORM nowadays, but unfortunately that's not the case with GORM. With a not-so-readable seedDatabase method, models now can have configurable initial entries. It’s a bit odd to use reflection to run a future method that may have different return types, but that's what I was able to come up with so far.
Conclusion
While the proof of concept code is not production-ready, it serves as an excellent starting point. Not everything should be taken as gospel, but you’ll see it closely resembles what we’re developing at Infinite, the apple of my eye.
The idea of having a codebase that changes very little over time is paramount to me. I’ve learned that relying on a very opinionated library, even with Clean Architecture, will eventually cause big issues. HTMX and Alpine seem to be a good compromise, and I don't foresee the frontend code changing that much over the years.
Sure, if your frontend relies heavily on client-side interactivity, going with this approach might add more complexity than it's worth. However, for us mere human developers of common web applications, this new approach is certainly intriguing and probably worth a shot.
Stay tuned to the blog for further updates on architecture and methodologies. And let me know in the comments — do you think this new way of creating full-stack apps is fascinating or just odd?
Comments