
The Clean Coder Golden Rules
When writing professional code, it is crucial to adhere to best practices, especially when transitioning from different programming languages or working under time constraints. This article aims to serve as a comprehensive guide to ensure that your applications are not only secure but also easily maintainable by future developers.
This article will be periodically updated, so it is advisable to bookmark it for future reference. Without further delay, let's delve into the essential guidelines.
1. Encapsulate Primitive Types and Strings
One fundamental rule in clean code development is to avoid the direct use of primitive types. Instead, embrace the concept of encapsulation by using custom types or objects.
By doing so, you can enforce validation rules that not only prevent potential issues but also ensure data integrity. This practice aligns with Rule #3 of Object Calisthenics by Jeff Bay.
Never place blind trust in user inputs, data from APIs, databases, or any form of external input without first converting it into trusted objects or custom types. Always employ factories and constructors when handling raw, untrusted data to ensure that you have control over its validation and integrity.
For instance, when dealing with custom strings, consider the following approach:
For custom numeric types, like floats, you can implement a constructor with additional validation checks:
2. Utilize a Proper Software Architecture
Regardless of whether you opt for Clean Architecture or prefer a simpler pattern such as Model-View-Controller (MVC), always employ a well-defined architecture that promotes code maintainability.
Avoid relying solely on the default file structure provided by your framework, as this can lead to complications when you need to adapt to changing frameworks or perform upgrades.
An architecture that encourages dependency injection and repository patterns is often the best choice for ensuring the longevity of your code, which may need to remain viable for several years.
3. Grasping the Essence: What, How, and Why
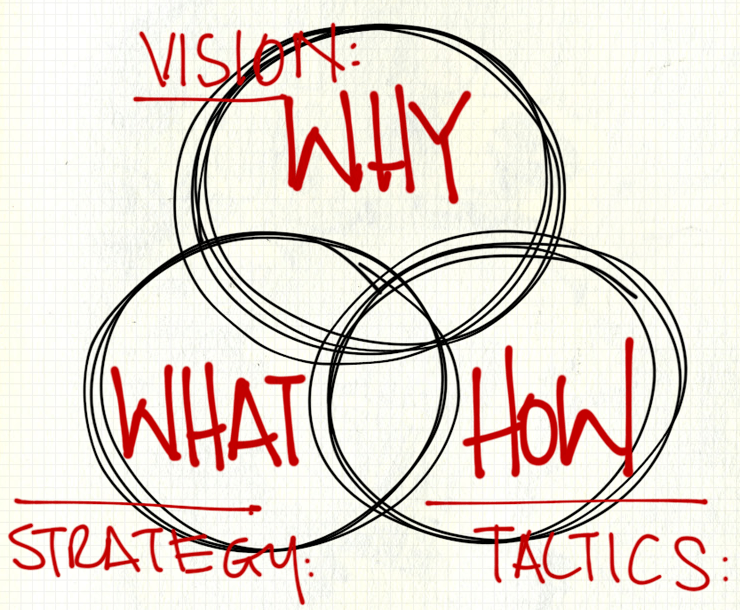
Before you even consider delving into the code, it's absolutely crucial to have a complete grasp of the problem and its solution. One must comprehend what the software is designed to accomplish, the manner in which it achieves these goals, and fundamentally, the reasons behind the functionalities—both in terms of what it does and how it accomplishes these tasks.
Let's start with the 'what'—arguably the simplest aspect. Set aside the source code for a moment and direct your attention to the endpoints. Investigate what the software is capable of, its requirements, and its outputs. Test it thoroughly, exploring each endpoint and every conceivable use case. Put yourself in the user’s shoes. It’s quite surprising how many developers never experience their own creations from a user’s perspective, even briefly. The most effective way to understand the user is to become one.
In instances where the software is still in the conceptual stage, jot down the intended purpose for each endpoint. Outline what it should accomplish, determine the necessary inputs from the user, and what you plan to deliver in return. When I begin coding, my initial step is to articulate the purpose of my method or class. I don't start with code; instead, I describe the mission in straightforward English.
Next, we venture into the 'how.' If the software is already in existence, immerse yourself in the source code, from the top down. Understand the flow of information, its manipulation, storage, and the APIs in play. This stage is undoubtedly challenging and may raise numerous questions, especially if the code is technically complex. Don’t fret—just note down any uncertainties and ideas for the time being.
If you're initiating the coding process, translate these method missions into sub-steps, yet still in plain English. Sketch out the steps you believe are necessary to fulfill the mission. Then, start coding, tackling each step methodically. Your code should mirror the step descriptions seamlessly, making comments redundant. The intent of the code should be self-evident, unmistakably clear.
The final piece of the puzzle is the 'why.' This involves understanding the rationale behind the software’s actions and the reasons for its particular development approach. Review your notes. You might have observed redundant information requests, missing authorizations in routes, or code segments that are paradoxical or unnecessarily complex. Don’t hesitate to reach out to previous developers or product managers to clarify any doubts.
Coding fundamentally centers on automation, yet the essence of software engineering diverges, rooted deeply in logic. Hence, embarking on the coding journey necessitates a comprehensive understanding of your product, the foundational technology, the challenges to be addressed, and the envisioned functionality of your solution. Begin by tackling the problem manually, sans code, to thoroughly grasp both the requirements and the most efficient pathway to resolution. Immerse yourself in the user's experience.
Diving into automation without fully understanding the process can lead to substantial challenges, squandering both time and effort. When confronted with unfamiliar concepts, it’s worthwhile to invest a few moments in educational resources—perhaps a quick tutorial on YouTube or a chat with an AI assistant—to bolster your comprehension.
4. KISS, YAGNI and DRY
When discussing clean code, we can't ignore these three essential principles. They work together to stress the importance of avoiding overcomplication and unnecessary repetition.
"Keep It Simple Stupid" (KISS): Complexity should be avoided. If your code needs an elaborate explanation or numerous comments, it's a sign that something's amiss. Clean code should be easy to read and understand.
"You Ain't Gonna Need It" (YAGNI): Write code only when it's needed for the current requirements. Future-proofing should rely on sound design, not on adding features that aren't currently in use. Don't try to solve problems that don't exist by adding methods and fields that aren't used.
"Don't Repeat Yourself" (DRY): Avoid writing the same code multiple times. When you notice duplication, consider converting it into a helper method or a separate class, depending on the situation.
While striving to eliminate redundancy, be careful not to create overly generic functions with long return values or unnecessary complexity. Refer to the "Strike the Right Balance in Verbosity" rule to understand when and how to use DRY effectively.
To implement these principles effectively, consider adopting a "build-measure-learn" (BML) feedback loop. This iterative approach suggests writing new code only in response to actual project needs.
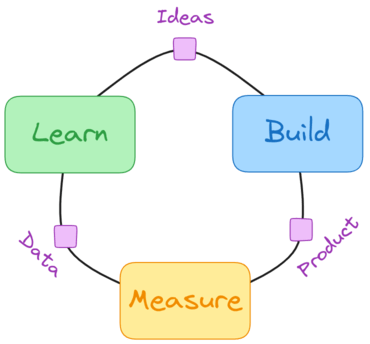
In the coding process, it's normal to write something and realize shortly after that it needs revision. Embrace this natural part of coding. The act of writing code is straightforward; the real challenge lies in making the logic clear and dependable. Avoid trying to predict the requirements of your next method or task; instead, proceed step by step.
Continuously assess whether the logic you're following is the most straightforward way to achieve the desired outcome. Only when you've confirmed that your automation works, performs efficiently, and maintains readability should you consider splitting the code into multiple methods or functions. This incremental approach ensures that your code evolves in a structured and reliable manner.
5. Strike the Right Balance in Verbosity
Clean code is not about brevity or verbosity; rather, it's about clarity and appropriateness. A frequent observation when reviewing code is the occurrence of either a couple of overly large methods handling numerous tasks, or the exact opposite — numerous small methods plus a mammoth main method. Ideally, a balanced approach with several moderately-sized methods facilitates easier comprehension of the developer's intentions.
The objective is for the code to be sufficiently descriptive to be understandable to the subsequent developer, yet not so elaborate that it becomes enigmatic. Variable names that merely replicate their values (unless formatting is an issue) tend to be redundant and can generally be streamlined. Overuse of nested functions and conditions may obscure the true intent; judicious use of intermediate variables to store results can enhance clarity.
This methodology can be approached in two phases. Initially, embrace detailed verbosity to draft your pseudo-code and establish a coherent logical structure. Subsequently, refine your code by determining which segments could be more effectively managed as auxiliary methods or integrated with other areas.
Only abstract code to auxiliary methods if the main method becomes overly lengthy (approximately 120-150 lines) or if the functionality is required elsewhere. Avoid unnecessary complications or embellishments. Should the need for an auxiliary method arise in another class, consider promoting it to a standalone utility function. Patience and adaptability are crucial—respond to genuine requirements as they emerge.
6. Use Conditionals and Booleans Strategically
Avoid enclosing your entire code within a single massive if block. The primary flow of your code should be clearly evident from the start, with minimal nesting. Conditionals should be reserved for specific scenarios where the standard flow doesn't suffice, and you need to incorporate additional steps.
If is fine, else is evil. Instead of relying heavily on if-else constructs, embrace alternatives like early returns or switch statements. else statements can lead to convoluted and difficult-to-follow code, which can become a maintenance nightmare. Remember that code is read more often than it is written.
The use of Boolean variables also warrants careful consideration. Developers tend to either neglect them entirely or overutilize them. When working with core or library functions lacking clear output or purpose indications, initiate a boolean variable to clarify its intent. This approach is also applicable to simplifying multi-line if statements into a single Boolean variable that succinctly communicates the objective.
7. Maintaining Code Cohesion
Every developer brings their unique coding style to the table. However, having three different ways to accomplish the same task scattered throughout your codebase or a mix of PascalCase and snake_case in different classes can lead to chaos.
Ensuring code cohesion is a fundamental practice. While there may be diverse coding styles in play, it's prudent to adhere to the prevailing style and conventions set by previous developers. However, this doesn't mean blindly perpetuating errors. If you encounter a mistake, rectify it in the new code before revisiting and correcting the same issue in the existing codebase, thus maintaining a sense of consistency.
Another aspect of cohesion often overlooked involves the organization of methods. In most programming languages, auxiliary methods should precede the main method. This convention harks back to the early days of computing when procedural programming was the norm.
While there may be instances where you need to reorganize the natural order of methods, like when creating classes where the constructor should be the first method, such reordering should be undertaken solely to enhance readability or adhere to well-established conventions.
8. Avoid Creating Misleading Terminology
This guideline could fall under the broader rule of "Maintaining Code Cohesion," but it's so frequently violated that it warrants its own emphasis.
In many codebases, I've encountered developers using multiple aliases for the same entity. For example, a user might be referred to as "user" in one file, "account" in another, and "person" in yet another. This inconsistency forces others to spend unnecessary time deciphering if different terms refer to the same entity, leading to confusion and wasted effort.
Moreover, developers sometimes introduce abstract concepts that lack concrete meaning in the code. Consider a policy-based permission system where a term like "hasPrivilegedRole" is used. Upon investigation, it turns out that there is no "privileged" concept; all roles are identical except for their attached policies. The developer's intention was to denote a role with a specific policy in a specific context. In such cases, a more precise name like "hasAdminDeletePolicy" would be far clearer and avoid introducing unnecessary complexity.
The key takeaway is to read your code as if you’re seeing it for the first time, without any prior knowledge. Eliminate aliases and abstract concepts that aren’t explicitly defined in the code. Ensure your variables and terms accurately reflect their intent and functionality. By doing so, you make your codebase more understandable and maintainable for everyone.
9. The Three-Step Code Verification
The process of triple-checking your code is an invaluable practice that ensures its quality and reduces common errors. Let's break it down into three distinct phases:
1) Initial Review: Before making any changes to the code, the first check is a mental one. Read the code aloud and immerse yourself in the methods and logic. The goal here is to gain a clear understanding of what the code does, how it accomplishes its task, and why it's structured in a particular way.
2) Ongoing Validation: The second check occurs after you've made your initial code adjustments. Instead of waiting until the entire refactoring or coding process is complete, perform this check after each sub-task is finished. Once again, read the code aloud, reinforcing your grasp of the code's purpose and how it all fits together. If everything aligns as intended, proceed with your commit. Repeat this process as you work through different parts of your code.
3) Pre-Pull Request Assurance: Upon completing the entire task and preparing to submit a pull request, take a brief five-minute break. Before seeking feedback from your colleagues, invest time in reviewing your own work. Address common errors such as grammatical mistakes, deviations from coding conventions, or overlooking linting and error checking. These errors are often avoidable and can be indicative of fatigue. By addressing them yourself, you save your potentially tired and overworked colleagues from dealing with avoidable issues.
10. Limit Your Code Sessions
Avoid the temptation to code for extended hours without taking breaks. While it may seem like you're being highly productive, the reality is that prolonged coding sessions often lead to overlooking crucial details, necessitating extensive code revisions later on.
Consider adopting time management techniques like the Pomodoro method. This approach allows you to maintain a sharp focus and a clear mind throughout your work. When you encounter challenges, resist the urge to spend excessive time (more than 45 minutes) on a single problem. Instead, transition to the next task or seek assistance from a colleague.
11. Embrace Collaboration and Seek Guidance
Regardless of your expertise, there will be times when you’re unsure about the clarity of your code or the suitability of a particular solution. It's essential to recognize that having doubts is not a sign of weakness; it demonstrates your willingness to step outside your comfort zone and improve your skills.
Remember, your colleagues are not adversaries but allies with the same goal — achieving success as a team. When faced with questions that don't have straightforward answers, reach out to your peers for their input. Encourage them to provide feedback on your thought process and be a team player.
Avoid making unilateral decisions when deviating from the group’s initial plan. Instead, communicate openly about the challenges you’re facing and the potential solutions you’re considering. Follow the 1-3-1 rule: first, describe the actual problem with details since your teammates don't have a crystal ball; second, present the three likely workarounds you’re thinking about or have considered; and third, share the solution you’re leaning towards and explain why. This approach ensures clarity and fosters constructive feedback.
However, be mindful that your peers are likely busy. If your code is readable and you need a simple confirmation or review, wait for the pull request process. Only seek your teammates' help when dealing with logic issues that impact multiple parts of the code or when you’re genuinely stuck and cannot find a way forward.
12. Test and Monitor
In software development, one undeniable truth prevails: things break. However, it's far more advantageous for them to break during the initial stages of development rather than in front of your users. Therefore, incorporating unit and integration tests is not merely recommended; it's an absolute necessity. If possible, extend your testing suite to include end-to-end tests for comprehensive coverage.
The time invested in creating robust tests pays off manifold. It ensures code consistency and mitigates the need for extended debugging sessions. This approach is a win-win scenario from every perspective.
Vigilance doesn't end with code deployment. Once your application is in production, maintain a watchful eye. Monitor response times, scrutinize error logs, and analyze access patterns.
Recognize that your application may eventually encounter misuse or exhibit unforeseen behavior. Waiting for users to report issues is an inadequate approach to user experience and can jeopardize your client base. Proactive monitoring is the key to preemptively addressing potential problems and ensuring a seamless user experience.
13. Add Informative Logs and Responses
When it comes to debugging applications, it often involves asking users how to recreate issues and sprinkling in a fair share of temporary "console.log" and "var_dump" statements. But with so many print functions, it's all too easy for someone to forget them in the code, inadvertently exposing sensitive data.
To avoid this predicament, consider using logs to record useful errors and providing users with concise yet informative messages. For instance, if your application's database goes offline, delivering default error messages like "Error connecting to server on socket X" isn't very user-friendly and potentially reveal information about your database to attackers.
Instead, opt for a message like "DatabaseConnectionError." It's user-friendly, letting API consumers know it's not an issue with their payload. Plus, it's easy to translate on the user interface without revealing too many unnecessary details. You definitely want to steer clear of displaying a full-blown stack trace when errors occur. That's like serving a feast to potential attackers.
This tip comes in particularly handy when working with factories within a for loop, for example. You might use a "continue" to skip an iteration when something goes wrong without logging why. Then a user reports having X items, but the application only shows half. You can still use "continue" to keep the flow going, but make sure you log the error with enough information for you or the operations team to easily figure out what's happening.
14. Shift Away from an Exception-Driven Mindset
If you come from a background in web development-focused languages, you may be accustomed to using try-catch and exceptions extensively. However, newer languages tend to be designed for concurrent and multi-threaded programming, thus the use of panics and exceptions is discouraged for several reasons:
a) Predictable Control Flow: Panics and exceptions can lead to non-deterministic program behavior in multi-threaded environments, making it hard to understand and reason about program execution.
b) Resource Management: Avoiding panics helps ensure proper resource cleanup, preventing resource leaks like memory or network connections.
c) Concurrency Safety: Panics can disrupt the safe and explicit communication model between co-routines, potentially introducing unexpected behavior.
d) Code Readability and Debugging: Panics can make code harder to read and debug, especially in multi-threaded contexts.
e) Performance: Exception handling can introduce overhead in time and memory usage, which can be problematic in performance-sensitive systems.
f) Philosophy of Error Handling: Modern languages promote explicit error handling as a core principle, treating errors as values rather than exceptional events. This approach enhances code clarity and maintainability.
It is advisable to handle errors gracefully using "if err != nil" statements, which may appear verbose but align with the idiomatic way of error handling in modern languages. With practice, you will become accustomed to this approach and benefit from its clarity and maintainability.
15. Caution with Type Assertions
When dealing with raw data, it's often necessary to assert its data type and subsequently transform it into a trusted format. Always begin by clearly labeling the raw data with a prefix that signifies its nature.
Furthermore, ensure that you validate these type assertions before proceeding to further operations. This practice enhances code clarity and minimizes the risk of unexpected data mismatches or type-related errors.
The approach to checking for the existence of a key and the type of its associated value can vary depending on the programming language in use. In our example, we are utilizing Go, a language that inherently supports multiple return values from a single function. As a result, verifying both the existence of a key and the type of its value is pretty straightforward.
16. Short PRs: Quicker Reviews, Faster Merges
A smaller pull request (PR) generally undergoes a more thorough line-by-line review. A research published by Graphite suggests that the optimal size for PRs involves changes to three or fewer files. However, this ideal is often challenging to achieve in complex enterprise architectures.
In scenarios involving the implementation of a new feature using Clean Architecture and Domain-Driven Design (DDD) patterns, it is typical for my team and I to modify approximately 8-15 files across various layers. This range serves as our upper threshold. Exceeding this limit may indicate an overestimation of the task’s complexity or an attempt to incorporate too many features within a single PR.
Establishing a standard for the expected number of file modifications per feature can streamline the review process. Limiting each PR to a single feature not only expedites reviews but also ensures they are conducted with greater diligence compared to more extensive PRs that affect numerous files. This approach helps maintain focus and improves the quality of both the codebase and the review process.
Comments