
Overfed, overthought, overasked. Stop sabotaging your AI.
More thinking tokens should mean better output. 121 dispatches across five providers proved that wrong, along with most other assumptions about how AI reasoning actually works.
Code review is a useful proxy for how AI models reason: it requires reading comprehension, domain knowledge, structured judgment, and severity calls. The goal here is to extract practical insights about how reasoning budgets, scope, and review architecture interact in a real pipeline, not to rank models.
So this became a fun exercise:
- 121+ review dispatches;
- one Go production codebase;
- five providers;
- thinking budgets from 8k to 48k tokens;
- three scope tiers: T1 (~1k LOC), T2 (~2.3k LOC), T3 (~4.8k LOC);
- two review styles: split (three focused personas for Security, Quality, and Coherence) and lean (one unified reviewer covering all dimensions).
The assumption going in was Daft Punk's mantra: work it harder, make it better, do it faster, makes us stronger. More thinking, better output, just keep turning the dial.
That assumption broke almost immediately. And the ways it broke map, almost too neatly, onto four lessons.
For methodology, prompts, and raw data, see the technical details at the end.
| Model | Architecture | Thinking Budget | Sweet Spot | Notable |
|---|---|---|---|---|
| Kimi K2.5 (Turbo) | MoE (1T / 32B active) | 8k–48k | 16k | Most verbose; collapses above 16k |
| Qwen 3.5+ | Undisclosed (likely MoE) | 8k–32k | 12k–16k | Shared token pool; best T3 depth |
| Claude Haiku 4.5 | Dense | Uncapped | N/A | Honest self-assessment; fast |
| Claude Sonnet 4.6 | Dense | Uncapped | N/A | Unique cross-system findings; slowest |
| Seed 2.0 Pro | Undisclosed (likely dense) | 8k–32k | 16k | Best constraint compliance; late addition |
Work It Harder
Giving a model more time to think can make it find fewer bugs. Not plateau. Actively regress.
Kimi K2.5 Turbo found all four known vulnerabilities at 16k thinking tokens. At 48k, triple the budget, it found zero. Same code, same prompt. Shell injection got demoted to a note. Weak RNG became "acceptable for test data". Every certified bug was identified, rationalized, and dismissed.
This wasn't just a high-budget problem. At 12k, the coherence reviewer dropped to zero blockers, a valley of doubt at one specific budget that recovered at the next one up. The working range is exactly one setting wide.
Why would a trillion-parameter model talk itself out of correct findings? Because it doesn't reason with a trillion parameters. Kimi is a Mixture of Experts (MoE) model: 1T total, but only 32B active per token.
Imagine a hospital where every patient sees a different small team of doctors, chosen by a receptionist who only reads the first sentence of their complaint. The hospital has hundreds of specialists. Each patient gets a handful. And which ones depends on routing logic that can get stuck in a loop, sending the case back for more opinions until the original diagnosis gets talked out of the room.
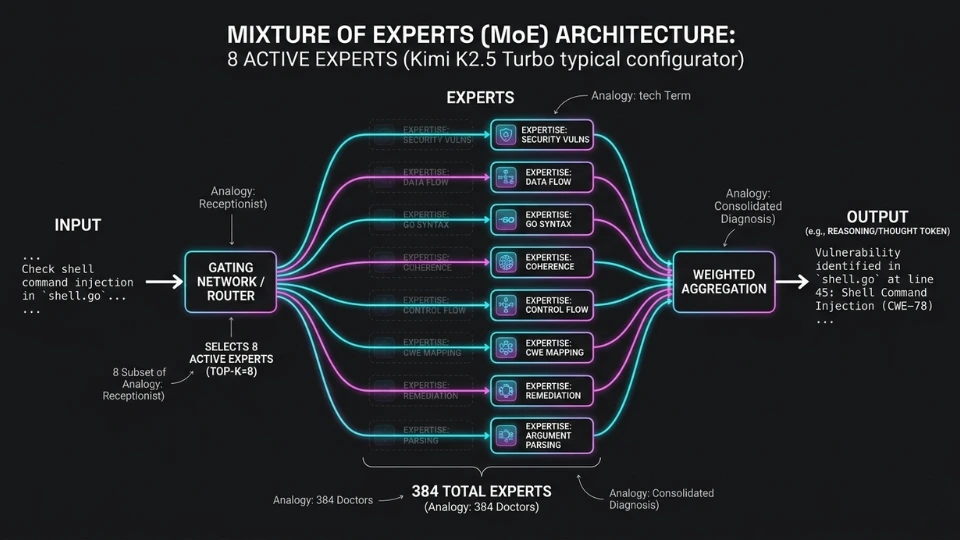
That architecture is better at memorization than reasoning. More experts help the model know more things. They don't help it think harder about what it knows.
MoE routing likely isn't the only cause. Reinforcement Learning from Human Feedback (RLHF) training rewards caution, and a model trained to avoid false positives can learn that "maybe this isn't actually a problem" is the safest output at any length. Architecture and training interact. This benchmark can't isolate which dominates.
But the pattern is consistent: the most verbose model in public benchmarks, given more room to talk, talks itself out of correct answers.
Kimi K2.5 Turbo (MoE, 1T/32B active) on Fireworks. Dispatched via OpenCode CLI. Four certified bugs: weak RNG (CWE-338), shell injection, path traversal, YAML billion laughs. At 16k: all four detected. At 12k: 0 (valley of doubt). At 48k: all four dismissed. See also: overthinking survey and reasoning completion point.

If MoE architecture drives the regression, does every MoE model collapse the same way?
Not quite. Qwen 3.5+ on Alibaba Cloud Model Studio is another likely MoE: Alibaba doesn't disclose its parameter count, but the open-source Qwen3.5 family uses MoE (397B total / 17B active).
It showed a softer version of the same regression: its quality reviewer self-corrected to zero findings at 32k, but its security reviewer climbed from 7 to 11 across the same range. Dimension-specific.
Qwen also has a mechanical constraint Kimi doesn't share. On Model Studio, thinking and output tokens share a 64k-token pool. At 8k thinking, 57k of output space remains. At 32k, only 33k. What looks like better calibration is partly the model running out of room to talk.
Qwen's hybrid reasoning mode, designed to switch between thinking and non-thinking, may also give it a better "stop thinking" signal than Kimi's routing. Same architecture family, softer failure.
Qwen 3.5+ on Model Studio: shared 65,536 token pool. Quality at T3: ~100 blockers at 8k (noise), 10–20 at 12k–16k (actionable), 0 at 32k (over-correction). Security at T3: 7 at 8k, 11 at 32k (monotonic improvement). Same model, opposite behavior by dimension.
Claude models (Haiku, Sonnet) are dense: every parameter active for every token, no routing, no expert selection. They showed no budget regression. Haiku truncates large files and Sonnet runs 2-6× slower, but neither talked itself out of findings at higher budgets.
Seed 2.0 Pro (ByteDance), whose open-source sibling is explicitly dense, corroborated this from a third architecture. It showed the opposite budget pattern from Kimi: at T1, 8k thinking produced 8 blockers (over-escalation), 32k produced zero blockers with 3 well-reasoned notes: the cleanest result in the benchmark.
More room to think meant more room to refine rather than more room to doubt.
The emerging pattern: MoE models with tunable budgets hit a ceiling where more thinking hurts. Dense models improved or held steady.
A caveat: architecture claims are inferred from public documentation and latency profiles. Kimi is openly MoE. Claude has historically been dense, but Anthropic doesn't disclose specifics per model version. Qwen and Seed are inferred from open-source siblings.
If turning up the budget doesn't reliably help, what lever actually matters?
Make It Better
Scope. Feeding a model more code, not more thinking time, unlocks findings that no amount of reasoning over a small codebase will produce. But only for some kinds of review. For others, more code makes things actively worse.
Some models hit a hard scope ceiling before the dimension-specific behavior even kicks in. Kimi completed 100% of reviews at T1, 60% at T2, 33% at T3. Above ~1,000 lines, something always broke: DNF, rubber-stamp, or hyper-criticism (one run flagged ~40 blockers on variable naming alone).
The practical sweet spot: ~2k LOC per dispatch.
T3 (~4.8k LOC) exists as a stress test to reveal how models degrade under pressure; nobody should be reviewing 5k lines in a single pass. Every model degraded there. When in doubt, chunk.
Within that ceiling, the benchmark tested three dimensions, Security, Quality, and Coherence, each as a separate focused persona.
Security scales with scope almost perfectly. Qwen at 16k found 0 security blockers at T1 (~1k LOC), 3 at T2 (~2.3k LOC), 8 at T3 (~4.8k LOC).
Finding vulnerabilities is trail-following: can untrusted data reach a dangerous sink? More code means more trails. Budget helps too (Qwen's security climbed from 7 to 11 between 8k and 32k), but scope is the stronger lever.
Quality gets worse with scope when the budget is wrong. Qwen at 8k on T3 produced roughly 100 blockers, almost all false positives. At 12k–16k, 10–20 actionable findings. At 32k, zero. A pattern matcher with too much room to write will fill it. With too little, it self-edits into silence.
Does this pattern hold beyond Qwen? Seed confirmed it from a second architecture. At 8k, its quality persona fixated on a single naming rule and flagged it 12 times, then created a file it wasn't asked to create. At 16k, it spread attention and stopped misbehaving. Low budget narrows obsession. Moderate budget broadens judgment.
Coherence is where things get strange. On a large codebase, more thinking found more bugs in a clean curve, with three novel issues appearing only at 32k. At medium scope, the same persona peaked at a moderate budget and dropped. Same model, same job, opposite behavior at different scale.
Seed's coherence persona showed a variation: at 8k it found 6 blockers, at 16k it found the same issues plus 8 new ones but downgraded most to warnings. Budget didn't help it see more. It helped it judge better.
Qwen coherence at T3: monotonic increase from 8k (6 blockers) to 32k (9, with 3 novel). Same model at T2: peaked at 16k, dropped at 32k. Seed coherence at T3: 6 blockers at 8k (over-escalated), 2 blockers + 13 warnings at 16k (calibrated). Budget helps security find, helps quality filter and helps coherence judge.
Why do the three dimensions behave so differently? Because they're different tasks wearing the same label.
- Security is trail-following: can untrusted data reach a dangerous sink?
- Quality is pattern matching: does this code meet standards?
- Coherence is mental model building: what breaks at the edges when the whole system interacts?
Each task has its own relationship with budget and scope. Tuning one variable for the wrong task makes things worse.
Seed's lean reviewer false-passed at 8k on T3: 4,786 lines of code with known vulnerabilities, marked clean. But the split security persona at the same budget found 5 real blockers in 72 seconds.
The lean reviewer spread 8k tokens across three dimensions and ~5,000 lines. The focused persona spent the same tokens on one task. Seed's long-context benchmarks predict exactly this kind of scope-induced failure.
Seed T3: lean 8k = false pass (0 blockers), lean 16k = 1, lean 32k = 4. Split security 8k = 5 blockers (72s), split security 16k = 5 (73s), split security 32k = 4 (254s). The lean false pass happened while the split persona found 5 real issues at the same budget.
That raises a structural question. If each dimension needs different tuning, should they run as separate focused passes or as one unified reviewer?
Do It Faster
Three specialists or one generalist. The same question every hospital, every engineering team, every consulting firm eventually asks. A single unified reviewer is 2-5× faster than three focused personas. That's the difference between a review that fits in CI and one that doesn't.
Split vs lean at T3 (~4.8k LOC): Qwen at 8k: 479s vs 98s (4.9×). Qwen at 16k: 313s vs 111s (2.8×). Sonnet: 714s vs 352s (2.0×). Haiku: 163s vs 61s (2.7×).
But you don't hire a generalist because they're cheaper. You hire one because they see things specialists don't. And vice versa.
The focused coherence persona catches subtle behavioral bugs: a function that works in isolation but breaks in sequence, a symlink and a copy operation with inconsistent rules. The unified reviewer misses these. The bigger the codebase, the wider the gap.
On some bugs, though, the generalist wins. The unified reviewer caught path traversal 6/6 while the split persona caught it ~4/6. The generalist read file-handling code as one connected system. The specialist proved the exploit more rigorously but spotted it less often. One finds more. The other proves more.
Why would a single reviewer catch what three focused ones couldn't? Because the job description reshapes what the model sees. Tell a model "you are a security reviewer" and exploitable data flows light up. A resource leak that isn't exploitable? Invisible.
Sonnet's unified review found exactly that: a file handler resource leak and a crash on zero-length input, two bugs absent from the entire split benchmark. The generalist follows whatever looks wrong. The specialist follows whatever matches the brief.
Seed showed the most extreme version of this tradeoff. At 8k on T3, its lean reviewer false-passed: 4,786 lines with known vulnerabilities, marked clean. At the same budget, the split security persona found 5 real blockers in 72 seconds. The generalist spread 8k tokens across three dimensions and ~5,000 lines. The specialist spent the same tokens on one job. It's an attention budget problem, not a quality gap.
At 32k, the picture inverted. The lean reviewer found symlink traversal and YAML deserialization. The split found shell injection and TOCTOU. Both independently caught YAML. Same model, same budget, different method, different bugs.
There's a catch, though: speed only works if the model can process the full input. Haiku finished T3 in 61 seconds but truncated a key file at line 500. It silently dropped part of the input, reported 12 inflated blockers, and rated its own confidence 2 out of 5. It knew it was working blind.
The fastest model in the benchmark was also the most honest about its limits. That's worth something.
Split and lean serve different stages. Use lean for T1–T2, where scope is narrow and speed matters. Use split for T3, where focused attention earns its overhead. And if you can afford the latency, Sonnet's lean pass finds cross-system bugs no one else sees.
Makes Us Stronger
No single provider, architecture, or budget wins across every axis. The finding is precisely that. But the way each model fails reveals something more interesting than a leaderboard.
Kimi found zero unique bugs across 27 dispatches. Everything it surfaced, someone else had already caught. At the same speed (48s vs 60s), Haiku found four times the security blockers and surfaced bugs no one else did.

So much for the trillion-parameter advantage. But raw count doesn't tell the whole story either.
Sonnet found fewer bugs in total than Qwen. By that metric alone, it loses. But every finding came with a proof-of-concept payload, a full explanation, and a specific fix. It surfaced 10+ bugs no other provider found, including filepath.Abs defeating a traversal regex and argument injection via filenames interpreted as tar flags. And it did something no other model did: it withdrew its own false positives mid-review. The only model that corrected itself.
Is that better or worse than Qwen at 16k, which hit 8 security blockers in 77 seconds with unique finds including RTL Unicode overrides slipping through StripUnsafe and an RFC 5280 certificate path length contradiction? At 32k, Qwen found 11 blockers in 83 seconds. Barely slower, significantly deeper. It traded rigor for coverage, and depending on the job, that's exactly the right trade.
The tension underneath all of this: instruction following and finding depth don't come from the same place.
Qwen violated output constraints in 1 of every 3 dispatches, writing files and running tests it wasn't asked to run. It's the engineer who reads ahead, runs the edge cases you hadn't mentioned yet, and sometimes formats the report differently than you asked. The findings are real. The packaging needs supervision.
Seed was the opposite. One constraint violation across 121+ dispatches. Near-perfect format compliance. Its split security persona was remarkably budget-independent: same four core issues at every budget, with more thinking costing 3.5× more time for one fewer bug.
Seed T3 split security: 8k = 5 (72s), 16k = 5 (73s), 32k = 4 (254s). Core four at every budget: math/rand, shell injection, YAML deserialization, TOCTOU. Lean at same budgets: 8k = 0 (false pass), 16k = 1, 32k = 4.
When given a focused role, Seed doesn't need the budget dial. Its lean reviewer does: same model, same code, same 8k budget, and the lean pass false-passed while the split persona found 5. Obedient doesn't mean shallow. But obedient and unfocused can mean blind.
This maps onto a choice every team makes: the creative who pushes boundaries and occasionally breaks the build, or the reliable one who follows the spec and never surprises you. The answer is knowing which role each one plays.
And then there's confidence. Most models rated themselves 4–5 out of 5 regardless of output quality. Seed gave itself 5/5 on the false pass and 5/5 on the 5-blocker run. Haiku was the exception. It consistently rated itself 2–3, and it was right every time. The smallest model may simply lack the capacity to fake certainty.
Our Work Is Never Over
The assumption that more thinking produces proportionally better results doesn't hold. What holds is knowing which dial to turn, how far, and for what.
More thinking helped security almost not at all. It helped coherence up to a point, then hurt. It helped quality calibrate, but pushed too far, it produced silence. For MoE models, 16k is the ceiling. Past that, they start un-thinking. Dense models are more forgiving, but diminishing returns still apply.
More code helped security consistently, broke quality when the budget was wrong, and sent coherence in different directions depending on scale. The practical ceiling is ~2k LOC per dispatch. Every model degraded beyond that. When in doubt, chunk.

In practice: run the lean reviewer after every small phase of development, where scope is narrow, speed matters, and the generalist catches cross-system bugs that specialists miss. Dispatch the split review before creating the PR, once enough code has accumulated for focused personas to find meaningful interaction surfaces.
Match the model to the job. Seed for reliable format compliance, the kind of reviewer who follows the spec and never surprises you. Sonnet for deep unique findings with proof-of-concept payloads, the auditor you bring in when you need to know why, not just what. Qwen at 16k for the best coverage-to-speed ratio. Haiku for fast honest triage, the only model that consistently knew when it was guessing.
And ignore confidence scores. Every model lied about its certainty except the one too small to fake it.
The underlying pattern has a name: the Reasoning Completion Point. Every model reaches a moment where it finishes thinking and starts un-thinking: qualifying its findings, softening severity, rationalizing away what it already found. Past that point, more tokens don't add reasoning. They add doubt.
Recent work on optimal exit points confirms this across large-scale benchmarks: the curve peaks, then drops. The mechanism is signal-to-noise degradation: the model's own thinking tokens flood its attention, diluting the original input.
Humans do this too. A doctor who orders one more test. An engineer who runs one more simulation. A writer who revises a sentence until the life drains out of it. The instinct to keep working past the point of usefulness is a reasoning problem. These models just make it measurable.
The dial has a sweet spot. Finding it is the work. And like the song says, that work is never over.
This is a case study, not a controlled experiment. One language (Go), one production codebase, four ground-truth bugs. The sample is directional, not definitive. All dispatches used the same system prompts across providers, no provider-specific tuning. Full result matrices.
Comments