
gzip, bzip2, xz, zstd, 7z, brotli or lz4?
Not long ago, I found myself pondering over the choice of a compression tool for backups in Infinite Ez, our self-hosted container platform that transforms a single server into a fully-fledged PaaS. Ordinarily, gzip would be the obvious choice, but I began to question whether it was truly the best tool for the job.
Could I, perhaps, achieve a better compression ratio with relatively low resource usage or a quicker process? There was only one way to find out – it was time for a proper benchmark test.
Decision Criteria
Determining the best compression tool can be rather tricky, as there are multiple variables to consider, each carrying different weights depending on your specific use case. When deciding which compression method reigns supreme, it's essential to establish what you need to prioritise and what you can afford to compromise on.
- RAM: Some algorithms can be quite memory-intensive, occasionally to the point of consuming all your available RAM. What's the maximum amount of memory you're willing to allocate to the compression process without jeopardising the stability of your entire system?
- Time: How long can the compression and decompression processes take? Is this a scheduled task, or does your user need results promptly? Remember, time also translates to CPU usage. A lengthy process will occupy CPU cores that you won't be able to utilise for other tasks.
- Ratio: How costly is storage (and bandwidth) for your particular use case?
The type and size of the files involved will also influence the final outcome. There are certainly more criteria to consider when scoring the best tool, but the three mentioned above are likely to have the most significant impact. If your scenario differs significantly from the one used in this benchmark, it might be worth conducting your own tests to make an informed decision.
The Rationale

RAM
The Infinite Ez documentation recommends that users have a minimum of 4 GB of system memory to handle a production workload. Most users won't be running their servers at over 90% resource usage all the time, so we can reasonably assume there will be around 400 MB available for compression tasks. For decompression, which may be handled by multiple users simultaneously, 200 MB should be okay.
To be on the safe side, lets assume a maximum of 200 MB of RAM usage for compression and 100 MB for decompression, earning a perfect score of 5 points. For every additional 50 MB used, we'll deduct a point. Seems fair, doesn't it?
Time
Infinite Ez is designed to manage workloads that typically involve anywhere from 30 to 100 containers. A solid backup strategy usually entails at least daily backups stored on external servers. The daily backup window, which generally occurs at dawn, lasts for a maximum of 6 hours, with half of that time often consumed by network transfers.
This leaves us with about 3 hours for compression in the best-case scenario. With an average of 30 to 100 containers, that means we have 3 hours divided by 30 or 100 containers, resulting in a maximum of 6 to 1.8 minutes per container.
Anything exceeding 2 minutes will score 0 points, while each 20-second increment will earn 1 point, with results under 20 seconds receiving the maximum score of 5 points.
Decompression, however, is a different matter entirely. A good disaster recovery plan hinges on the ability to recover data quickly and reliably. In this case, time is of the essence. A delay of just 1 minute could lead to thousands of pounds in losses, depending on the situation.
For decompression, anything over 30 seconds will score 0 points, with each 5-second decrement earning 1 point, and anything under 10 seconds achieving the maximum score.
Ratio
Most users will be running container setups that typically consist of a popular database paired with an application built using a dynamic programming language. We consider a container running MariaDB alongside PHP and WordPress to be a good representative example. A tarball container image generated by podman or docker save for this kind of setup weighs in at around 1.6 GB.
These days, it’s hard to find storage cheaper than what object storage providers offer. At the time of writing, 1 TB of storage costs roughly $6 with providers like Backblaze or IDrive E2. This means each GB of data our customer stores costs about 0.006 cents.
For a daily backup of 30 to 100 containers, each at 1.6 GB without compression, the daily cost would range from 0.28 to 0.96 cents. While that’s not a huge amount, we need to keep at least 15 days’ worth of data, which brings our monthly total to between $4.32 and $14.4, plus any bandwidth costs you might incur depending on your provider. And yes, there will be dragons.
For instance, AWS charges 0.09 cents per GB of egress traffic. In a non-compressed scenario, we’d be transferring between 48 GB and 160 GB daily, resulting in an additional $4.32 to $14.4 per day. Multiply that by 30 and you have a monstrous monthly cost.
Of course, you could opt for the object storage solution from your data center to avoid egress fees or choose a data center that charges very little or nothing for bandwidth. However, since this is a simulation for situations our customers might encounter, we need to be cautious and plan for a rather challenging scenario.

So, how much of a ratio do we need? We should aim to reduce our data as much as the available RAM and time will allow. Ideally, we're hoping for at least a 1:4 ratio, meaning we'd only need to transfer 25% of what we calculated for the uncompressed version.
In terms of scoring, a ratio of 2 or less is a definite no-go, earning 0 points. For each increment in ratio, we'll award 1 point, capping out at 5 points when the ratio exceeds 6.
The Contenders
When using a Unix system, you'll likely have some of these tools installed. Let's take a moment to understand a bit more about them before we dive into the benchmark results.
gzip (v1.13): This is the most popular of the bunch and the go-to solution for many users. Created by French computer scientist Jean-loup Gailly and American software engineer Mark Adler back in 1992, it's based on the well-known Lempel-Ziv coding (LZ77) algorithm. Its speed and efficiency make it a favourite for compressing files quickly.
bzip2 (v1.0.8): Developed by British open-source contributor Julian Seward in 1996, who also created Valgrind and Cacheprof, bzip2 employs the Burrows–Wheeler transform algorithm. It's often seen as the middle choice in most discussions about compression tools, striking a balance between speed and compression ratio.
xz (v5.6.2): Known for being the compression powerhouse, xz was created in 2009 by Lasse Collin and Russian programmer Igor Pavlov, who is also the mastermind behind 7z. XZ recently made headlines due to an infamous backdoor incident affecting versions 5.6.0 and 5.6.1. Like 7z, it uses the LZMA algorithm, which is renowned for its high compression ratios and efficiency, making it a popular choice for packaging software.
zstd (v1.5.6): Developed by Yann Collet in 2015 at Facebook, zstd is the "newest" kid on the block among well-supported compression tools. It's based on Zstandard, which combines LZ77 with a few clever tricks to enhance speed and compression efficiency. Zstd is particularly praised for its versatility, offering a range of compression levels that allow users to tailor performance to their specific needs.
7z (v24.05): Created in 1999, 7z has gained popularity in Windows environments due to its high compression ratios and support for a wide variety of file formats. It uses the LZMA algorithm, which allows it to outperform many other compression tools in terms of efficiency.
brotli (v1.1.0): Developed by Google in 2013, Brotli is heavily used to compress HTTP content, particularly for web pages and resources. It's designed to deliver better compression ratios than gzip, especially for text-based content, making it a favourite among web developers looking to improve load times and reduce bandwidth usage.
lz4 (v1.10.0): Released in 2011 and developed by the same author as zstd, lz4 is widely used in real-time applications such as streaming. Its primary strength lies in its speed, allowing for extremely fast compression and decompression, which is crucial for applications that require low latency and high performance.
Results
To evaluate the performance of different compression tools, I set up a virtual machine with 4vCPU and 8GB of RAM, running Linux Kernel 6.10.7 on openSUSE MicroOS. The underlying hardware is composed of AMD Ryzen 9 7900 @3.7GHz processor, TeamGroup T-Force Delta DDR5-6000 memory and Kingston 512 GB KC3000 NVMe.
Compression Results
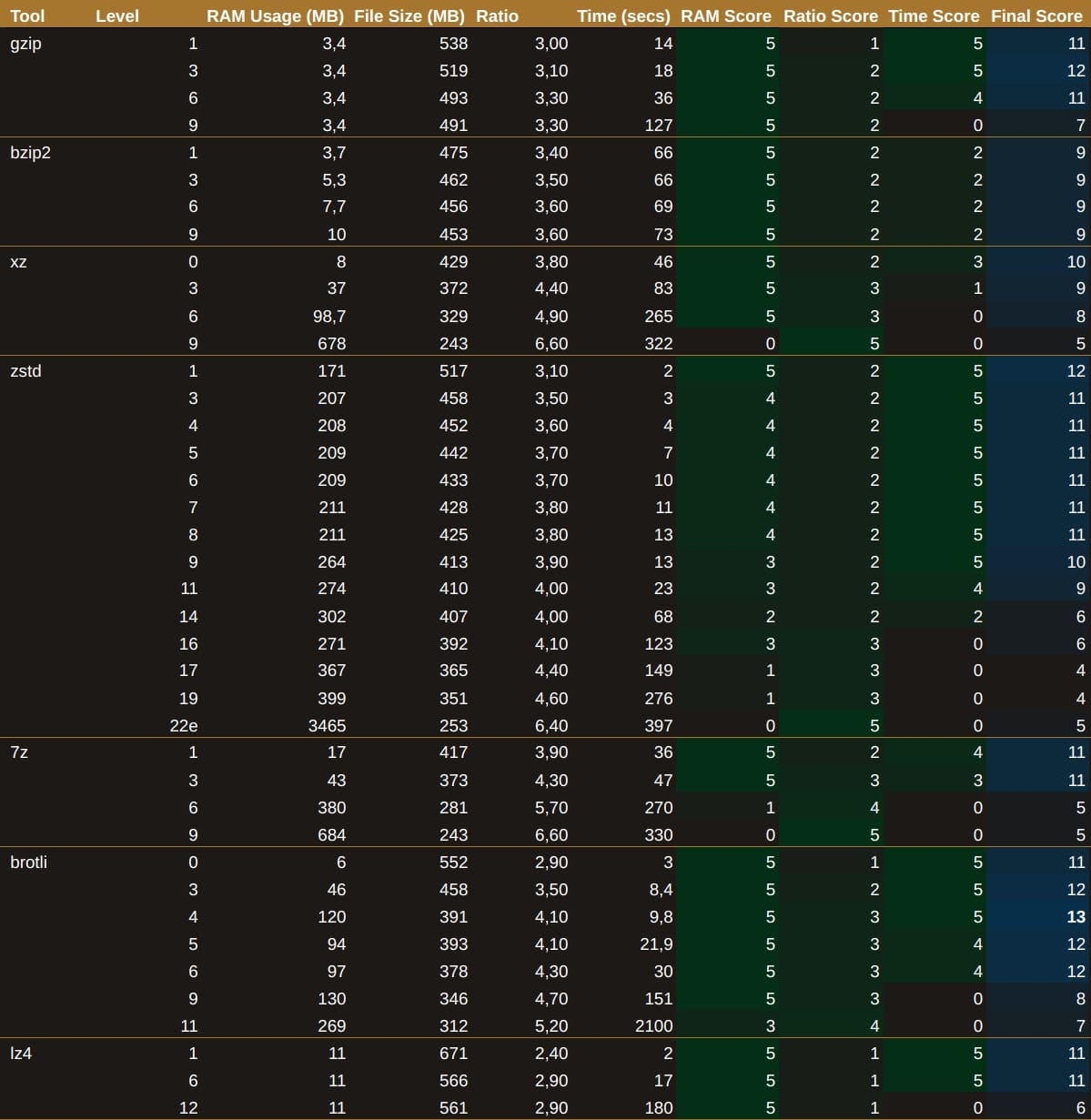
Initially, I was quite impressed with zstd at level 3, as it achieves a commendable 3.5 compression ratio in a mere 3 seconds. However, brotli at level 6 manages to achieve a 4.3 compression ratio in 30 seconds, which is our threshold for the maximum time score. This left me pondering whether to sacrifice 27 seconds for the sake of saving on storage.
Decompression Results
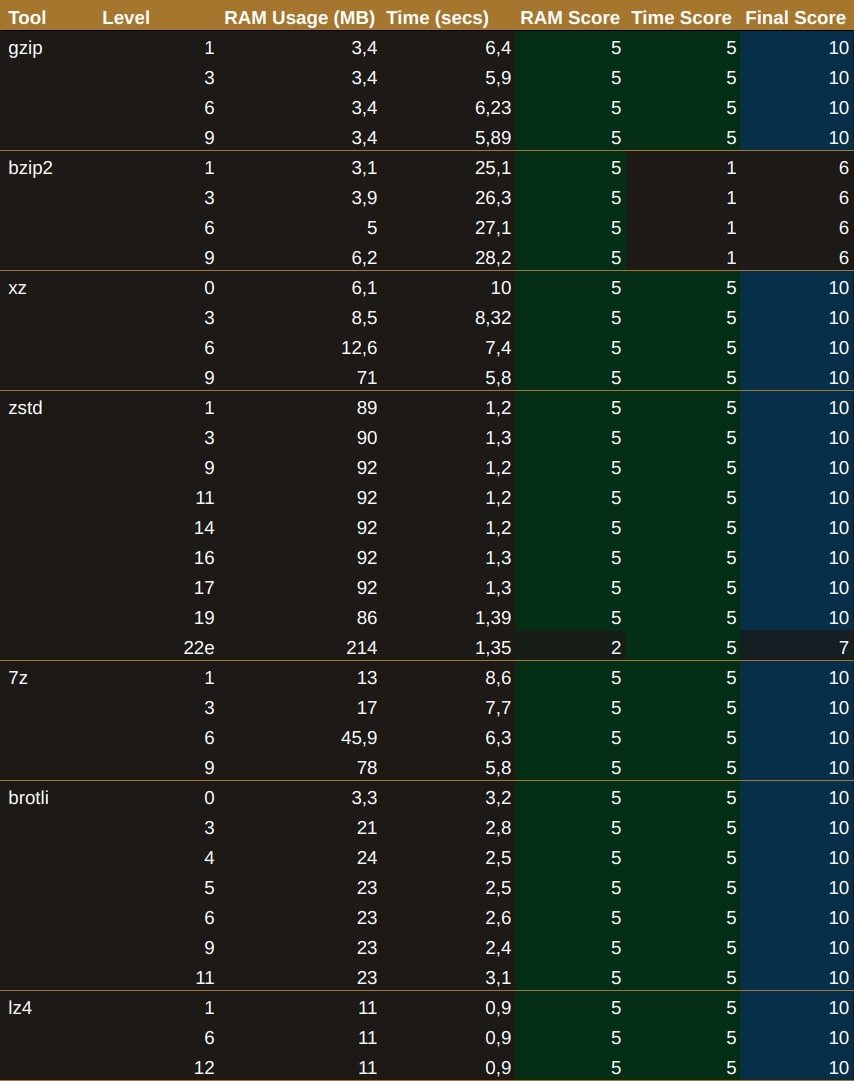
On the other hand, when it came to decompression, bzip2 was the only one that seemed a bit sluggish. The rest of the tools, however, were quite speedy and didn't gobble up too much memory — aside from zstd in ultra mode, which isn't surprising since the documentation stated this would happen.
Trying to Improve Settings
Most compression tools allow you to adjust one or more parameters to better suit your specific use case. Unfortunately, I didn't have the luxury of time to experiment with all the parameters across the various tools, but I definitely needed to resolve the zstd versus brotli dilemma.
I wondered if it was possible to speed up brotli if more memory was allocated. According to the CLI documentation, aside from the "level" parameter — which does increase processing time — the only other option that could potentially enhance the compression rate while consuming more memory is "--lgwin=NUM". However, this is already set to its maximum value by default, so it appears we're out of luck when it comes to customising brotli.
With zstd, however, the story is quite different. There are 22 options available to tweak the outcome. While we have some leeway with compression level 3, memory usage is already a concern.
We can't utilise long-distance matching or adjust the "windowLog", "chainLog" and "hashLog" parameters, as these would only increase memory consumption. The "overlapLog" parameter is only applicable in multithreading scenarios, and the "idm" parameter relies on long-distance matching. This leaves us with the options of "strategy", "searchLog", "targetLength" and "minMatch" to experiment with.
The default values for these parameters depend on the level you’ve set. Let’s take a closer look:
I was aiming for a compression ratio of 17 (4.4 => 365 MB), but wanted to maintain the memory usage of level 3 (207 MB) while achieving the compression time of level 11 (around 23 seconds). So, I decided to experiment using the default parameters for level 3 and change one parameter at a time:
Each parameter alone yielded minimal improvements, but when combined, they did provide a better compression rate — albeit at three times the time threshold. Memory usage remained consistent at 207 MB across all attempts.
I ran several scenarios with these parameters, but the best combinations only managed to achieve the compression ratio of level 6 while resulting in worse timing, all for the sake of saving just 2 MB of RAM:
In the end, the decision was clear: brotli at level 6 emerged victorious.
A Sudden and Welcome Twist
While experimenting with zstd configurations, I noticed that each level of compression was actually a blend of different settings. Out of sheer curiosity, I decided to run a test with brotli at levels 5 and 4 to see how they performed. Who knows, perhaps these other brotli levels would yield different results? To my surprise, they did!
brotli level 4, in particular, uses more memory than both levels 3 and 5 (which is rather unexpected), but it delivers the same compression rate as level 5 in half the time. I aimed for the stars and hit the moon, as they say. You can save 20 seconds of precious CPU time if you're willing to accept an additional 13 MB in storage.
After this revelation, I completed all the remaining tests between the mid-levels of zstd just to see if the results were linear. No surprises there; brotli level 4 is firmly crowned king.

Conclusions
Had I opted for the standard gzip without questioning what the best solution might be, I would have ended up with a 493 MB file after 36 seconds. By thoroughly examining the facts, I managed to achieve a 391 MB file in just 9.8 seconds. That's a reduction of 100 MB per container in the final file size and a rather impressive 3.6 times less wasted CPU time — all for a mere 100 MB increase in RAM usage, well within the established limits.
Since Infinite Ez will be deployed on thousands of servers backing up numerous containers daily, the reduction in final file size and compression time will undoubtedly save our customers a significant amount of money and CPU time. It's quite remarkable what a few hours spent on research and testing can accomplish, isn't it?
While my testing has provided valuable insights into the performance of different compression tools, there are still areas for further research such as different types of data, the impact of different hardware and kernel configurations and so on.
For readers who are interested in learning more about the subject and technical details, I recommend checking out the following resources:
Comments