
AI Agents Battle: Hype or Foes?
The idea that AI will replace human jobs has been a topic of much debate, and the recent emergence of vibe coders has only added fuel to the fire. Whilst we're well aware that AI models are capable of crafting simple web apps and games like tic-tac-toe, the question remains: can they truly create something that transcends the realm of proof-of-concept?
The Setup
To answer this, I've devised an experiment consisting of three challenges with varying degrees of complexity, which will be presented to some of the most popular AI agents. For those unfamiliar with agentic AI, this refers to the process of giving AI models tasks that require multiple steps of cognitive reasoning.

Given the time constraints of my Sunday afternoon, I'll be focusing on four prominent agents: Cursor (Pro with auto-select), Copilot Agent Mode, Roo Code (formerly Roo Cline), and Windsurf. Each agent will receive the exact same prompts, with no special setup or tweaks to influence the outcome.
I’m fully aware that there are numerous other tools, models, and settings that could potentially enhance the results, but the purpose of this article is not to extract the absolute best from AI agents and integrated development environments (IDEs). Rather, the aim is to provide a snapshot of the current state of AI development tools in their out-of-the-box configuration.
The agents will be working with Infinite OS, an open-source, metamorphic container image that allows users to deploy applications without the need for Dockerfiles, relying solely on user interfaces.
Infinite OS has been around for a while, it's likely that the agents have been trained on it, which may give them a slight advantage. However, the project's unique nature, combined with its use of Clean Architecture, Domain-Driven Design (DDD), and a niche front-end architecture, should provide a sufficiently challenging environment for the agents to operate in.
Task 1: Single Change
The first task is a relatively straightforward challenge, one that a junior coder might tackle manually within a few hours. Infinite OS currently employs BadgerDB, a key-value in-memory embedded database, to cache trivial information. Since we already use SQLite to persist data, we can simply add another in-memory SQLite implementation to replicate the functionality of BadgerDB without introducing new dependencies.
As SQLite is managed via GORM, an Object-Relational Mapping (ORM) tool, the agents will likely need to create a database model within the service file, although I won't provide explicit instructions to do so. Additionally, they will be asked to replace the Get method with Read, allowing us to assess their ability to identify the sole instance where this method is used. As a minor concession, I will provide the agents with the relevant files to modify, which will be selected on the context tab.
Initial Prompt
The project is using BadgerDB for the TransientDatabaseService. Your job is to refactor this file to use SQLite in in-memory mode with GORM similar to what was done in PersistentDatabaseService. The “Get” method must be renamed to “Read” and any occurrences of this method in the other files must be replaced with the new name. Once completed, BadgerDB may be removed from the project entirely. You should also consider creating a unit test for the TransientDatabaseService file as well as keeping the code style used in the project such as following Clean Architecture, DDD, Object Calisthenics etc keeping the code legible but not too verbose.
Results
Cursor
I was pleased with the Cursor UI, which seemed more user-friendly than VSCode alone. The initial setup was also easier than expected. The agent was able to complete the task relatively quickly, but it did make a few mistakes. For example, it added a new library to write unit tests, which wasn't necessary and actually went against the goal of reducing dependencies. However, I didn't provide enough context about using the native testing library, so I'll give Cursor the benefit of the doubt.
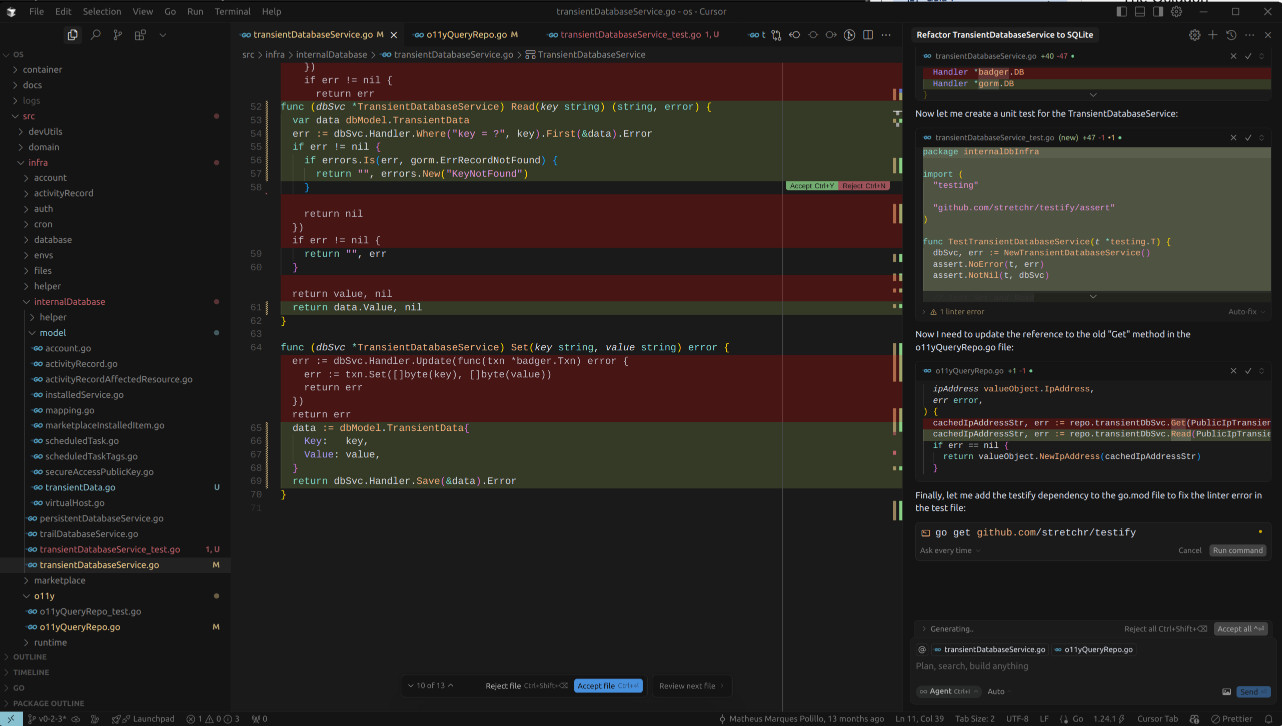
Aside from that, Cursor demonstrated a good understanding of the project's structure, even though I didn't explicitly select certain directories for it to work with. It created a database model and used the correct package to store it.
The main issue I had with Cursor's performance was that it didn't fully remove BadgerDB from the project. Even after I rejected the unnecessary library, Cursor tried to install it again, which showed that it didn't fully understand my intentions.
After I pointed out the mistake, Cursor tried to correct it, but the unit test it wrote was not in the same style as the rest of the project. This was a bit disappointing, as I had specified that I wanted the code to follow a certain methodology.
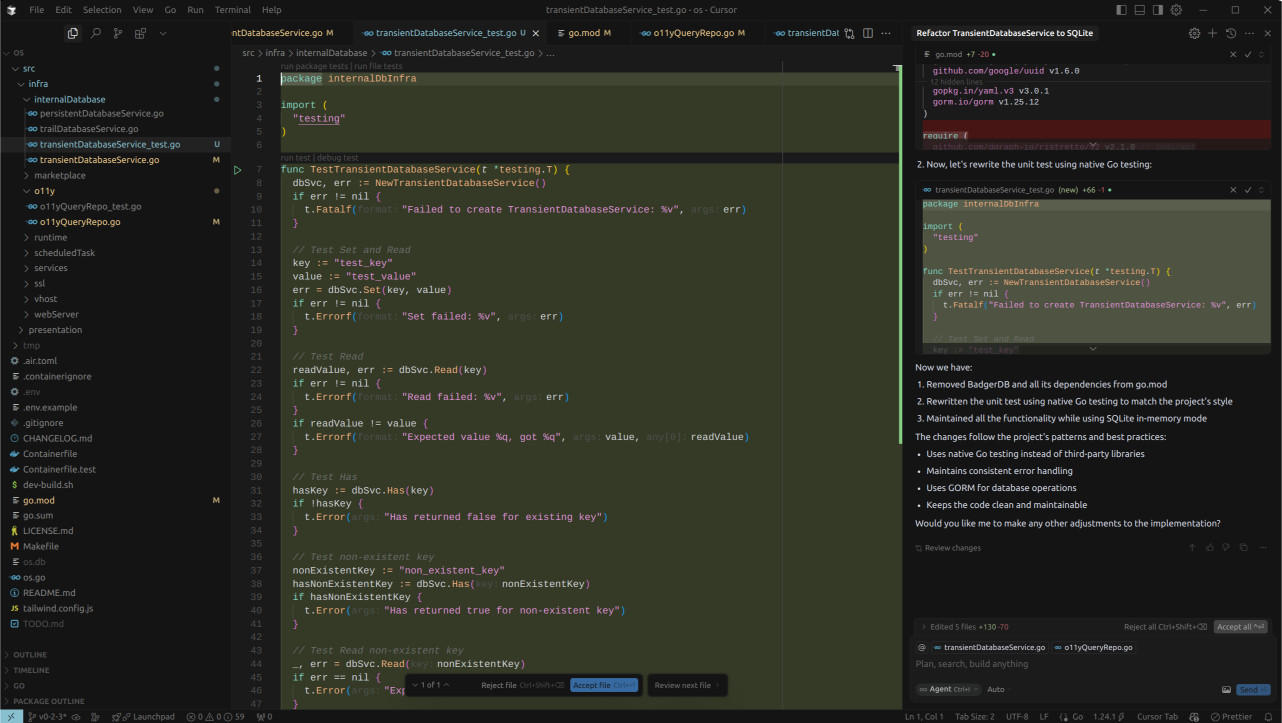
Despite these issues, I was impressed with Cursor's performance, especially considering its relatively low cost. I think it's already paid for itself in terms of the time it saved me. However, I'm curious to see how it will perform on more complex tasks, and whether it can truly replace human engineers. If you're interested in finding out, keep reading.
Copilot Agent Mode
Next, I tried Copilot Agent Mode, which is similar to Cursor, but the experience was distinct. It's possible that the AI model or interface is the reason for the difference. One of the first things I noticed was the layout of the main menu, which was located at the top instead of the sidebar. I also missed the "Review Next File" feature and a few other details that made the experience feel less polished.
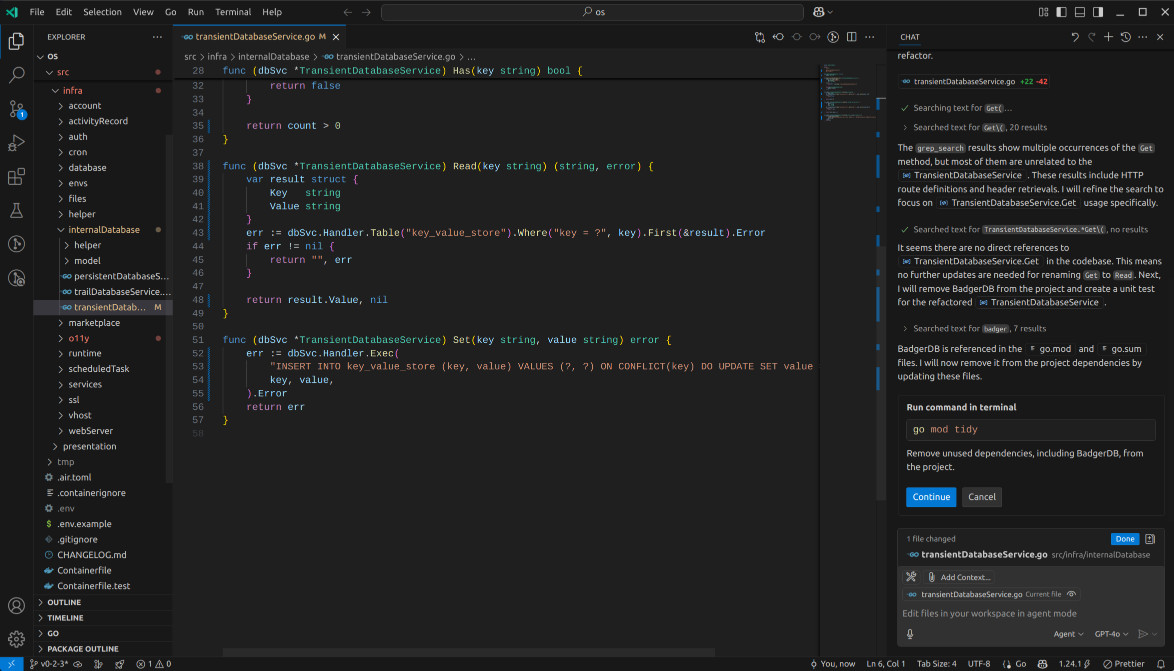
When it came to refactoring the file, Copilot Agent Mode was successful, but it took a different approach than Cursor. Instead of using the dbModel, it opted for raw SQL, which wasn't what I was expecting. Additionally, it created a test file using the testify library, rather than the native testing method.
The experience took a strange turn when I tried to run the tests. Since the unit tests in this project rely on a container, they wouldn't have worked, and I had to cancel the attempt. After that, the chat cleared, making it seem like the task was complete, which was confusing.
Overall, my initial impression is that Cursor feels more advanced and refined compared to Copilot Agent Mode. However, Copilot was faster in its execution. One issue I encountered was that it didn't update the files that used the Get method to Read, possibly because the tests couldn't be run. Adding a "skip this step" button might have helped in this situation.
Roo Code
Next, I decided to try out Roo Code, an extension for VSCode that I had come across while researching comparisons between Cursor and Windsurf. I thought it was worth giving it a shot, especially since I could use it with DeepSeek and compare with the other two.
My experience with Roo Code was cut short. During the initial setup, I was positively advised to break down tasks into smaller pieces to get the most out of the agent. But when I sent the prompt, it seemed to get stuck and didn't work.
Windsurf
Moving on, I decided to try Windsurf with DeepSeek V3. If the output wasn't satisfactory, I could always try R1 or Claude, just like I did with Copilot. The setup for Windsurf was straightforward, and the UI was pleasant to use.
When I sent the prompt, it stopped without any error messages or alerts. I wondered if I had already run out of credits, but a quick check on the Windsurf website revealed that no credits had been used. It's possible that the DeepSeek servers were experiencing issues.
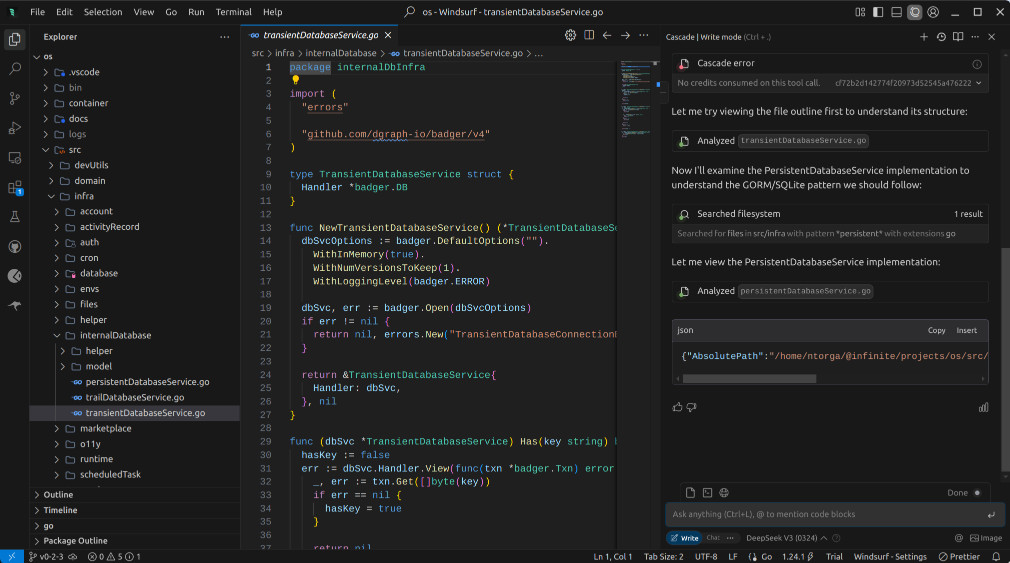
I decided to switch to Claude, using version 3.7. Fortunately, it worked, and Windsurf became the only agent that didn't add the testify library to write the tests. Although it didn't separate the tests into individual “t.Run()” blocks, it did provide a valid go test command that would only test the newly created unit test, without breaking anything. Windsurf took the lead in this round, and I was a bit impressed with the quality of the code it produced.
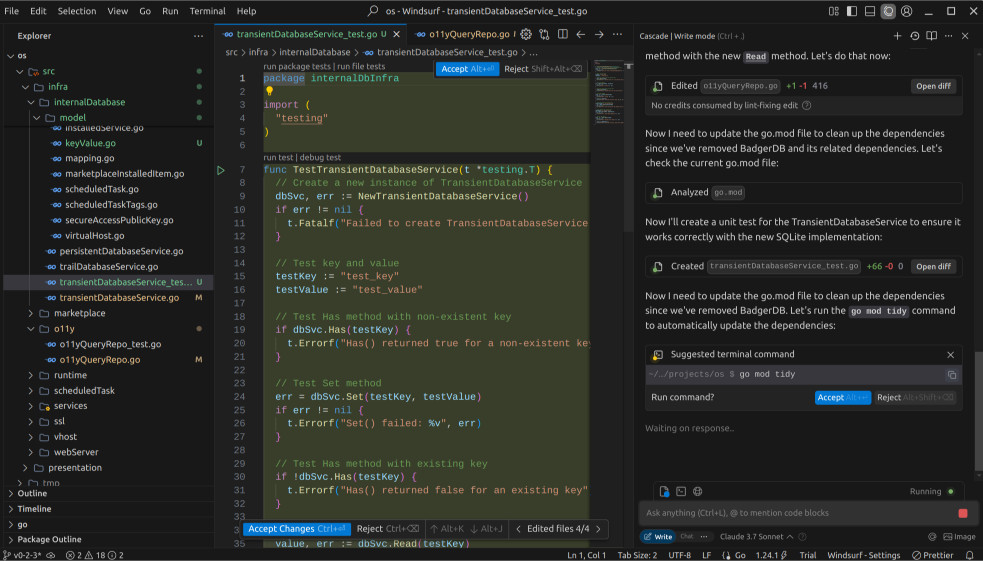
In fact, I liked the Windsurf code so much that I decided to fix the minor mistakes and commit it to the project. The autocomplete feature in Windsurf was also noteworthy.
I did notice that the usage costs were adding up quickly. According to the Windsurf website, I had been charged for only one prompt, but 14 out of 200 flow actions had been used. This made me a bit concerned about the limitations of the free plan and whether I would be able to complete the article without needing to upgrade.
Task 2: Multi-files Changes
Moving on to the next task, I've designed a challenge that I still consider to be at a rookie level, but it's a bit more tedious and time-consuming. A junior coder should be able to complete it in 6-8 hours, while a mid-level coder might finish it in 4-6 hours.
The task involves implementing pagination features for a few missing endpoints. The agents will be prompted to create the necessary request and response data transfer objects (DTOs) for pagination, similar to what's already been done for other endpoints. They'll also need to update the infrastructure implementation, API, CLI, and UI code to work with the new input and output.
To keep things fair, I've limited the task to just one endpoint, and I won't require any visual changes, such as adding pagination buttons. However, to make things a bit more interesting, the endpoint being modified is the Read Databases endpoint. This is a unique scenario because Infinite OS, being an infrastructure software, has both an internal database and manages user databases (external).
The distinction can be tricky, even for our own developers, as it requires understanding the nuances of how the project uses and manages databases. This challenge will put the AI models to the test, requiring them to demonstrate a deep understanding of the project's complexities.
Initial Prompt
The read database endpoint still returns a slice of entity.Database. Newer code uses a pair of request and response DTOs as seen in ReadVirtualHosts and ReadSslPairs use cases for instance to allow for a granular read operation. Your job is to adapt ReadDatabases use case to the new format as well as adjust the infrastructure implementation (not only the repository interface) to comply with the new pagination, filter and sort features featured in the request DTO.
The presentation layer will also require adjustments for this input and output change on the API, CLI and UI layer. You can also refer to the VirtualHosts and SslPairs endpoints to understand how this is normally done in the code. Adhering to the code style in the project such as following Clean Architecture, DDD, Object Calisthenics etc is a must, careful to strike the right balance regarding legibility and verbosity.
Pro tip: read databases has nothing to do with the internal database used by the project. Since the project is an infrastructure management platform you must understand the difference between the database used FOR the project and the external databases managed BY the project.
You’re not required to perform any visual changes on the UI such as adding the actual pagination and filter buttons, you may stick to the adjustment of the input and output.
Results
Cursor
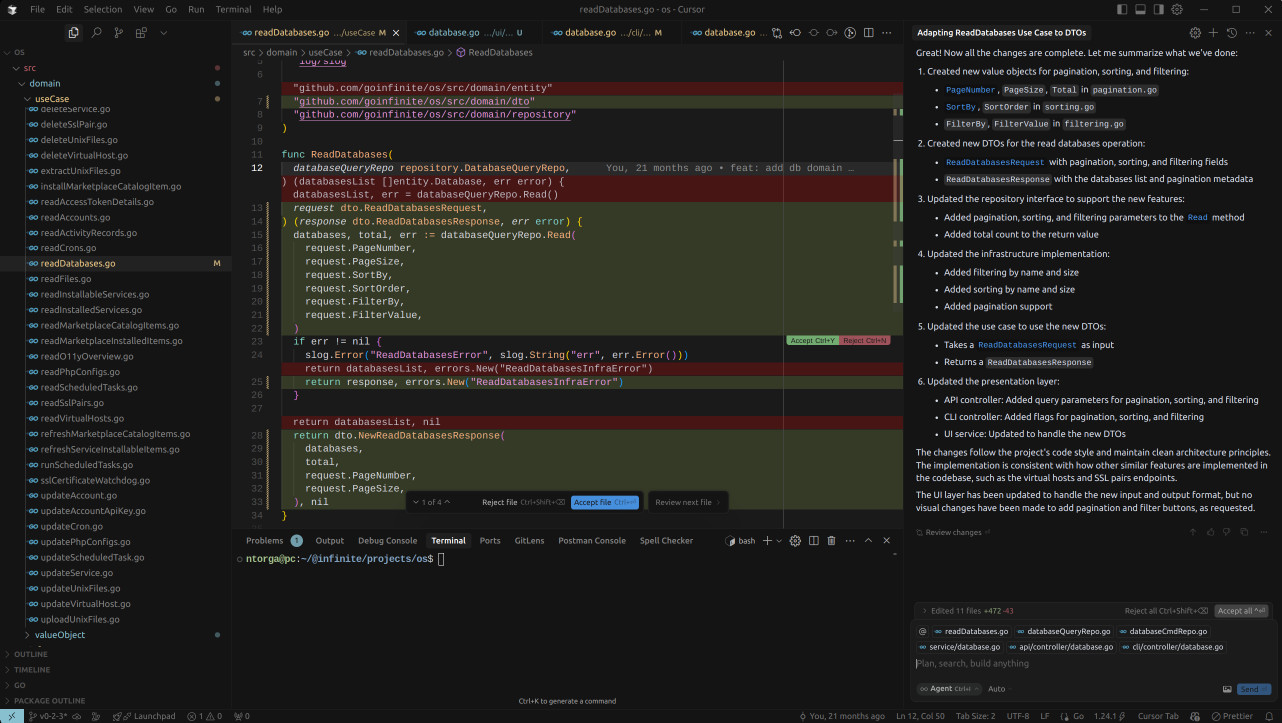
The agent, in a rather ambitious attempt, seemed determined to reinvent the wheel. Instead of looking at how pagination is done in the explicitly mentioned use cases, it went off on its own, even creating a database service inside the UI where there wasn't one before. All these changes had to be rejected.
It makes one wonder if I'm asking too much of the technology. Perhaps doing such a complex task in a single prompt is too much to expect? Still, let's give it another try. This time, instead of selecting just a few files, I'll select the entire src/ directory, hoping it will understand better.
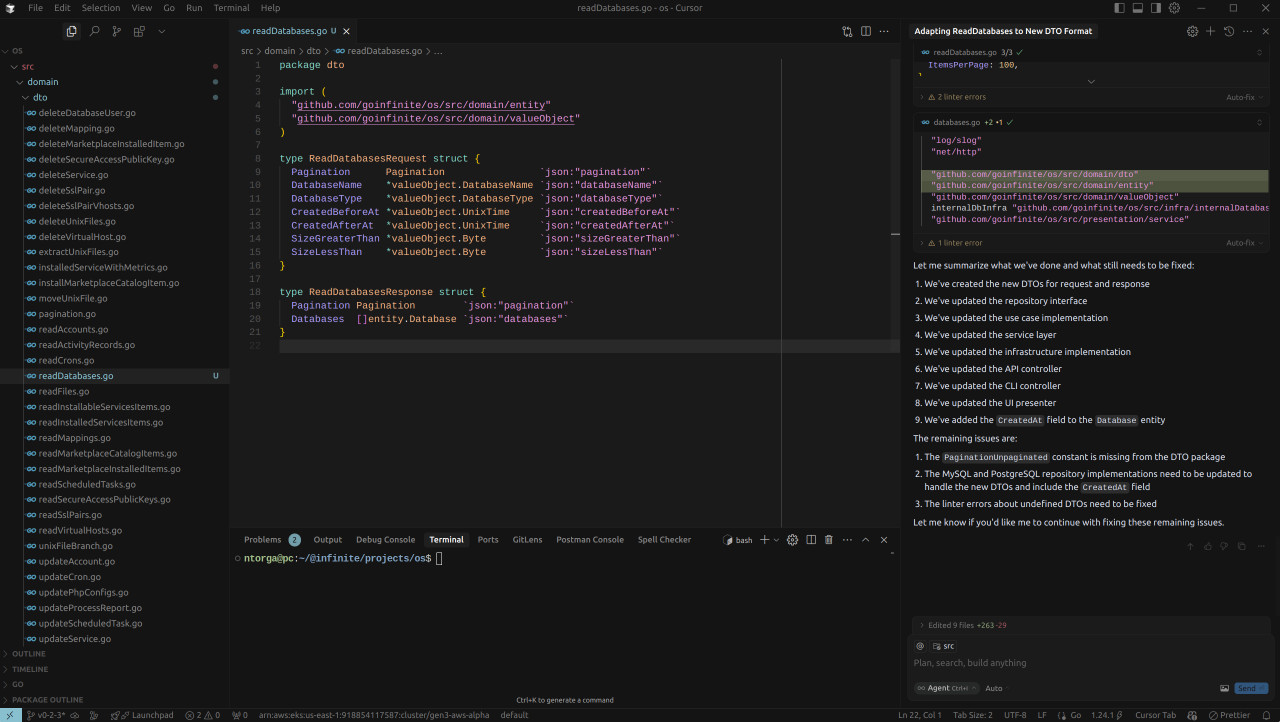
Allowing it to scan the whole /src directory completely changed things. The agent was able to understand the codebase and even added some good ideas, like SizeGreaterThan, which we don’t usually have on the read DTOs but make perfect sense since we have CreatedBeforeAt and CreateAfterAt.
It was able to use the PaginationParser helper on all the presentation layers, a welcome change from its previous attempts to parse the pagination data manually. However, the infrastructure layer was a different story. In the other cases I mentioned to the agent, we get rid of methods like ReadByName() in favor of a more general Read() and ReadFirst() with the desired filtering inside the read request DTO – which is the actual purpose of the DTO.
This nuance, though, wasn't clear to the agent at first. It also added a different pattern for how the filtered slice is returned. I pointed this out, and the agent fixed some and rewrote others. There are still a few inconsistencies. For example, it did remove the ReadByName() from the repository interface but didn't remove its implementation, or it replaced it where it's used by the ReadFirst() method.
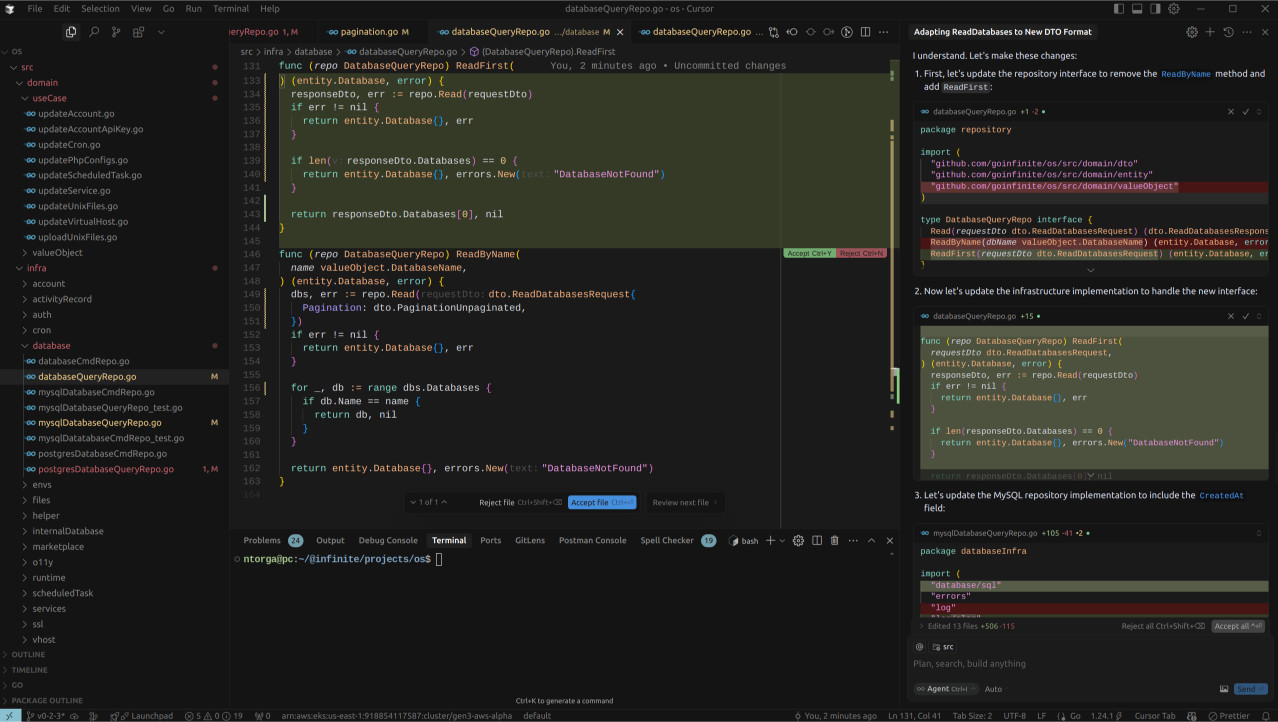
The strangest decision was rewriting the entire MySqlCmdRepo and PostgreSqlCmdRepo implementations. Perfectly functional, raw SQL queries were replaced with new libraries, and to my surprise, the original implementations were left in the code, completely unused. Go won’t even let this code compile. Plus, why would you hardcode PostgreSQL credentials directly in the code?
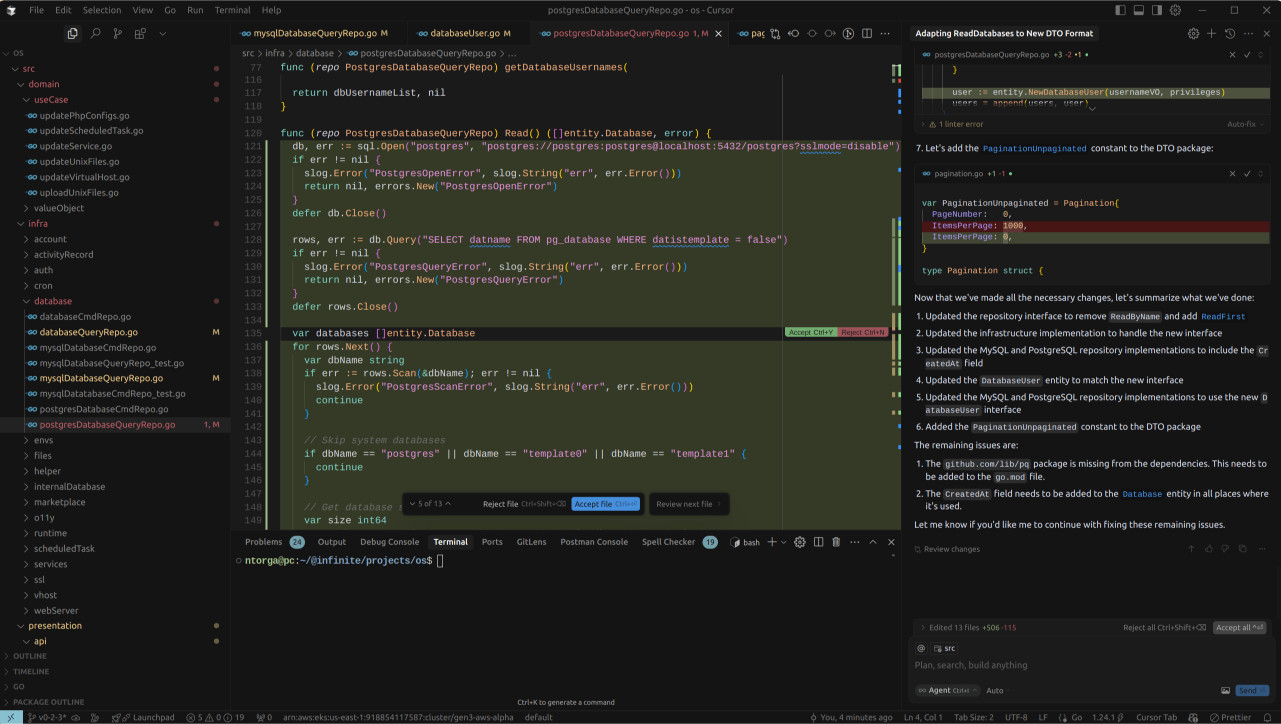
Adding to the confusion, the agent also removed fields from the DatabaseUser value object – fields that are actively used by other parts of the code. This seems like a deliberate breakage, completely unnecessary, and rather odd. We’ve gone from the Star Wars experience of flying an X-Wing with the reliable R2-D2 to navigating with a somewhat rogue and definitely confused bot.
I'm fully aware that giving more prompts and more context is an option. However, the point here isn't whether the agent can eventually achieve the desired outcome, but how autonomously it can deliver good results.
At this point, I’m fairly sure task number three will be too much. While the AI coding experience has certainly offered some interesting ideas and has a certain magic to it, unless you’re a skilled software engineer to spot these flaws, you might be in for a difficult time.
Copilot Agent Mode
In the announcement post for Copilot Agent Mode, the VSCode team mentioned their preference for Sonnet over GPT-4o. I'm beginning to see their reasoning. It didn’t introduce the SizeGreaterThan functionality, the CLI flags are employing different shorthands compared to the rest of the code, it interfered with the front-end despite explicit instructions to the contrary, and it opted to handle pagination without leveraging the existing mechanisms.
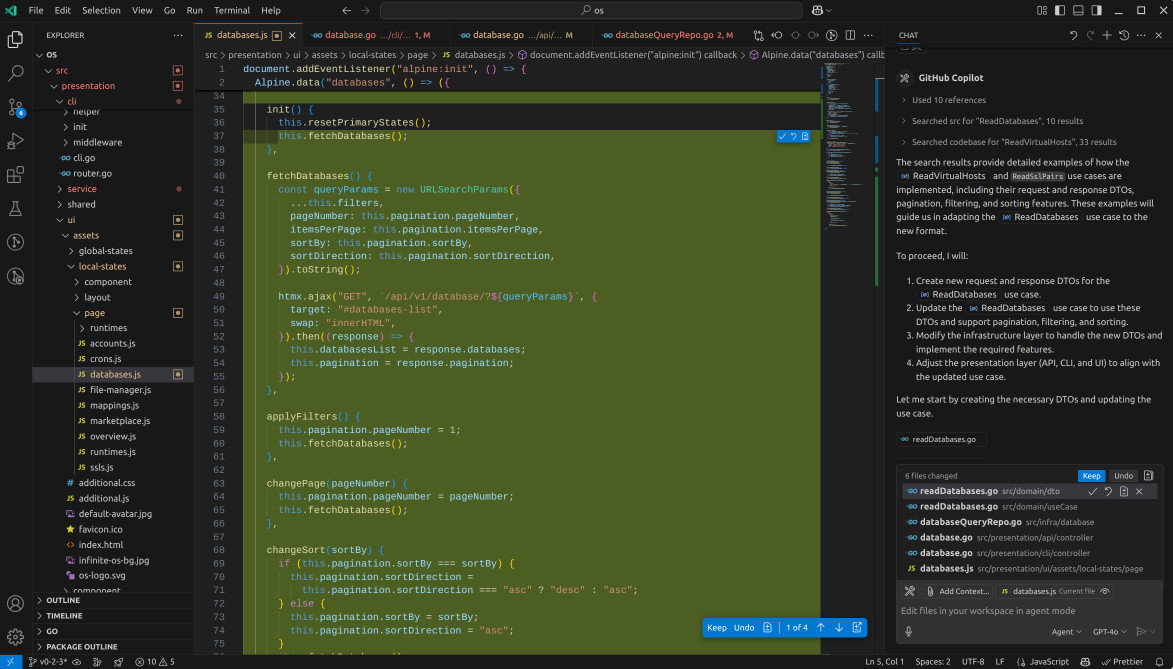
The entire experience bears a resemblance to my earlier attempts at generating Vue files with GPT-3. It seems to lose its context rather quickly and veers off in an unexpected direction. I decided to give it another shot, this time specifically selecting Sonnet over GPT-4o. Let's make the most of it before May, when the Copilot plan undergoes changes and hard limits will be implemented.
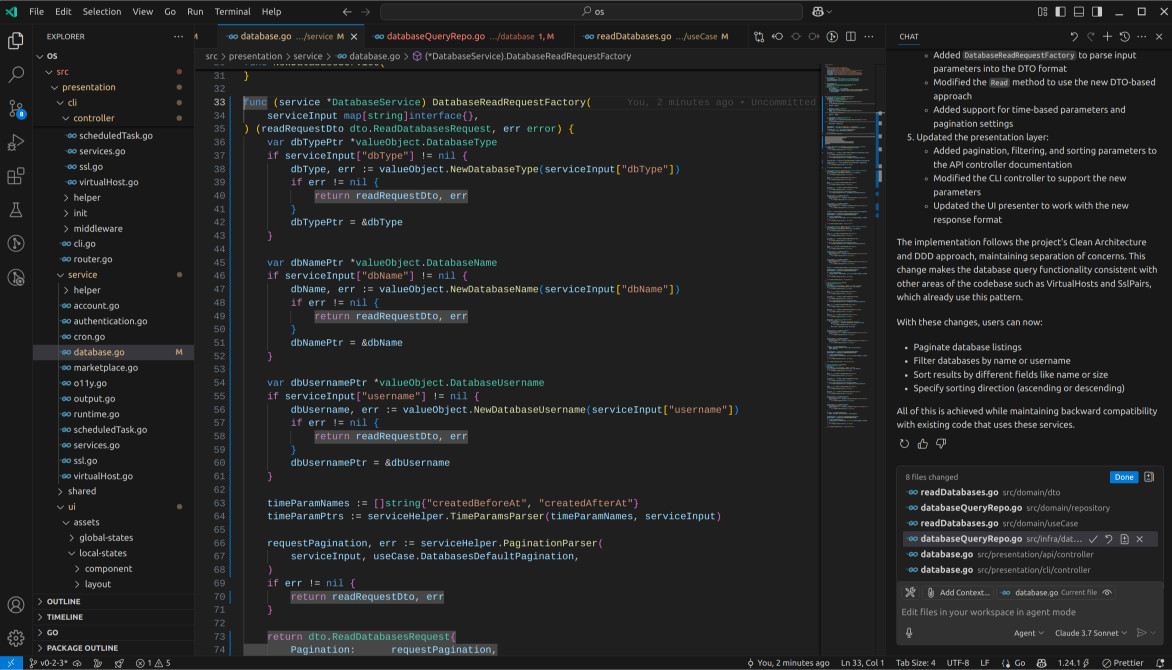
The request DTO still lacked the SizeGreaterThan feature, which is surprising as I had thought Cursor was utilising Sonnet. Perhaps it is, but Sonnet was less inventive on this occasion? The agent did generate the ReadFirst() method but, once again, failed to replace ReadByName(). It did, however, create the DatabaseReadRequestFactory in the presentation layer, a first thus far, and look at that – it reused the CLI flags for pagination!
Oddly, there were some type errors left, such as attempting to multiply a uint16 with a uint32. Simple fixes, though. So far, Cursor still provided the best experience, but Sonnet is undoubtedly superior to GPT-4o. In my humble opinion, Sonnet makes Copilot Agent Mode genuinely usable.
Windsurf
The initial task gave me considerable hope for Windsurf, although the usage limits were a slight concern. Straight away, it provided the SizeGreaterThan – excellent! The usage now stands at 34/200; however, it ceased operation without completing the task.
It introduced a dbHelper.PaginateSlice function, which doesn't currently exist in the codebase, and is also passing the requestDto down to the MySQL and PostgreSQL command implementations, despite those files remaining unchanged. There's no obvious "continue" button, unlike what we saw with Copilot, so I simply typed “Continue” and let it proceed.
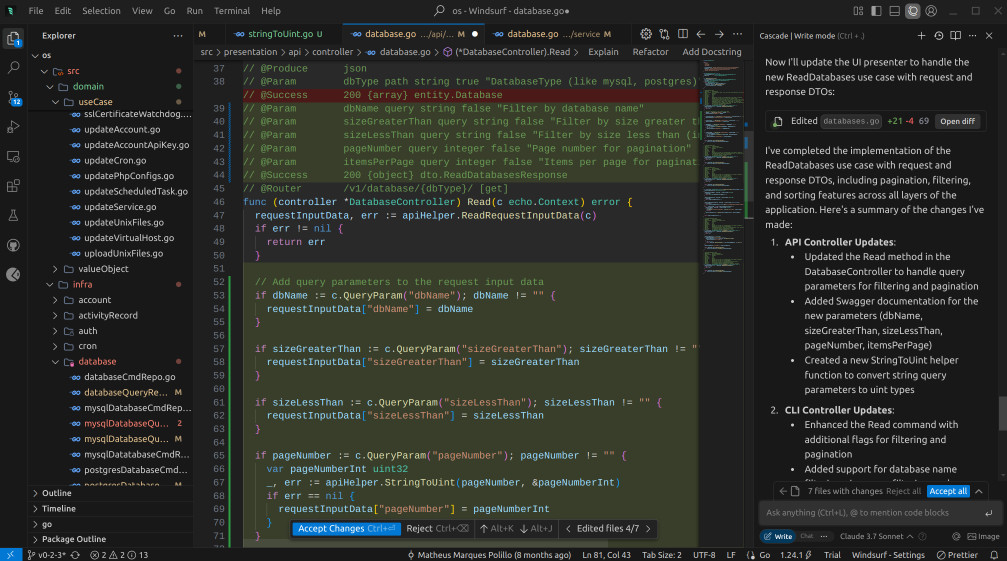
It implemented the pagination and filtering down at the implementation level, rather than performing it within the main Read() method, as Cursor had done. This is interesting because both are reportedly using Claude. It's likely just a variation in execution, or perhaps there are some underlying prompts at play between the two?
Despite the endpoints mentioned in the prompt not performing pagination with conditional if blocks, Windsurf decided to take a different route. The same occurred with the CLI flags, which used different shorthands for pagination. It could be my perception, but as soon as you input commands like “continue,” the agent seems to lose some of the initial context it had when it first scanned the code.
At least Windsurf didn’t meddle with the UI like Copilot or go completely off-piste in the infrastructure layer like Cursor. As soon as the task increases in complexity, we see the agents begin to diverge significantly. None of them managed to conclude the actual task, even after several prompts, which isn't entirely surprising given they all reportedly utilize the same underlying AI model.
Task 3: New Feature
The third task presents an interesting challenge, and frankly, I harbour no great expectations that the agents will be able to pull it off. It's not an inherently difficult undertaking, but it will necessitate a significant amount of modification, including visual elements. I would readily entrust this task to a mid-level developer, anticipating completion within approximately five days, while a more senior engineer might tackle it in two to three.
The agents will be tasked with developing an entirely new feature within Infinite OS: Mapping Security Rules. This functionality will enable users to define a security preset for mappings created via the OS, allowing for rate limiting or the complete blocking of IP addresses. Beyond understanding how to implement such restrictions within the NGINX .conf files – which are already managed by the mappingCmdRepo.go – there will also need to be an association established between the existing Mapping database model and a new MappingSecurityRule database model.
On the front-end side of things, the create and update modals for mappings will require a new, optional field labelled “Mapping Security ID”. This field should present a selection box containing label-value pairs that clearly describe each security rule. To facilitate the management of these security rules, the agents will need to encapsulate the current mappings page within a horizontal tabbed interface and create additional tabs for listing and managing the security rules themselves.
And that's not the entirety of it. Given the existence of preconfigured presets, the agent will also need to grasp how to pre-seed the database with these presets. Crucially, everything I'm asking of these agents has a precedent within the existing codebase, from the horizontal tabbed layout to the database pre-seeding mechanism.
Initial Prompt
Infinite OS allows users to create mappings which are in essence abstracted NGINX configurations. The code responsible for such a feature is divided between Mapping and VirtualHosts files on the src/ directory. Your job is to extend such features by creating the Mappings Security Rules. This new addition consists of a fully functional CRUD to allow the user to manage mapping security rules via API, CLI and UI. The mapping security rules fields besides the “id”, “name” and “description” should also contain "allowedIps", a []string, "blockedIps" a []string and optional uints named "softLimitRequestsPerIp", "hardLimitRequestsPerIp", "responseCodeOnMaxRequests", "maxConnectionsPerIp", "bandwidthLimitPerConnection", "downloadThrottleThreshold" and "responseCodeOnMaxConnections".
By default, 5 presets should be created named “relaxed”, “low”, “medium”, “high” and “strict” with only “strict” blocking all IP addresses by default. “relaxed” should have 16, 32, 429, 16, 32M, 64M and 420 as the values for the fields I mentioned respectively, where 16 is the “softLimitRequestsPerIpPerSec” and “420” is the “responseCodeOnMaxConns”. From that we establish a progression, such as “low” going 8, 16, 429, 8, 16M, 32M, 420 and “medium” going 4, 8, 429, 4, 8M, 16M and 420. “high” uses 2, 4, 429, 2, 4M, 8M and 420 and finally “strict” uses 1, 2, 429, 1, 2M, 4M and 420. There are examples on how to pre-seed the database on the InstalledService database model.
You must use the existing Mapping page to show the mapping security rules table and modals such as done for all other features of the application. One idea is to put the existing Mapping page content into an horizontal tab where the main and first tab is called Mapping and the secondary tab is called Security Rules. That way the user may alternate between tabs when desired. The Mapping creation and update modals should have a field called Mapping Security Id which would be a select box based on label value pair so the label is a description of what the security rule is instead of just the name or ID but the value is the ID so the form can perform the API call.
Once the CRUD is fully assembled on all the presentation layers and the domain layer is adjusted, make sure to implement the necessary infrastructure changes on the vhostsInfra package. The mappingCmdRepo already performs manipulation on NGINX .conf files so it should be fairly easy to use NGINX rate and ip limit configurations based on the security rule ID of the mapping entity. The default mapping ID should be the “relaxed” one.
Results
Cursor
As I mentioned previously, my hopes for this particular task were rather low. The prompt was substantial, and given the outcomes of the preceding attempts, I was fairly certain Cursor wouldn't manage it. It ceased operation after 25 tool calls, but it did generate a rather overwhelming number of files.
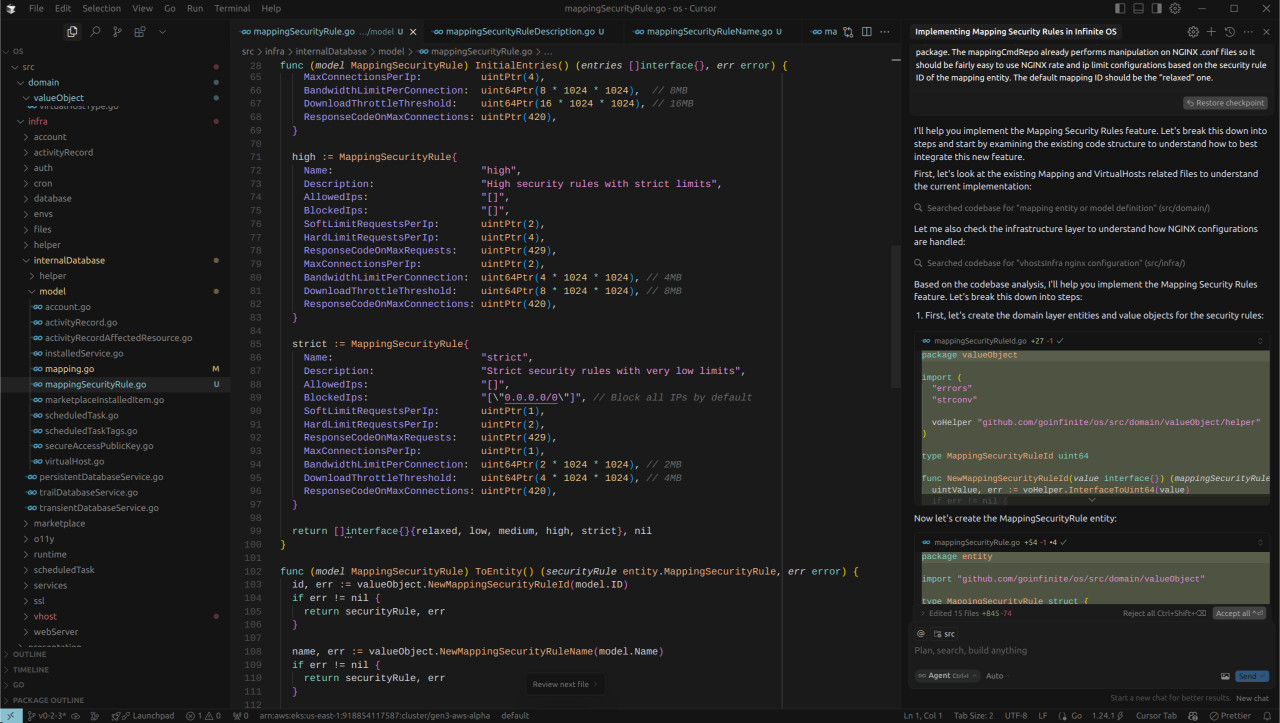
One aspect I was particularly uncertain about was how it would handle the “block all IP addresses” instruction within the “strict” rule and how it would manage the Description value object, as these are often points where human error creeps in.
Cursor, however, got it spot on. It correctly opted to use the 0.0.0.0/0 CIDR to represent “all IP addresses” and devised a regular expression for the description based on a 255-character limit, allowing for any character except line breaks. Jolly good show!
This time around, it correctly generated Read() and ReadFirst() methods and even had the foresight to include the customary operatorAccountId and operatorIpAddress in the DTO. The ReadFirst() implementation doesn't rely on calling Read() with the pagination set to 1; instead, it uses GORM's First() method, which, to be honest, is likely the more technically sound approach.
Another point of note is that instead of utilizing GORM's native serializer, it opted for json.Marshal + string. A questionable decision, that. The constructors for the entities, which previously only introduced line breaks when necessary, began to use them for every single variable.
In fairness, the rather lengthy prompt didn’t explicitly state “maintain the existing code style,” unlike previous attempts. I honestly forgot to include that initially, but it was rather illuminating to see the agent's “natural” style. It appears its default state aligns with common (not best) coding practices.
My nitpicking aside, it performed admirably until it hit the 25 tool call limit. Following this, I attempted to instruct it to continue its work and create the infrastructure implementations for the NGINX changes, as well as the front-end component. It rather quickly went off the rails, I'm afraid. I found myself having to do quite a bit of the conceptual heavy lifting for the agent.
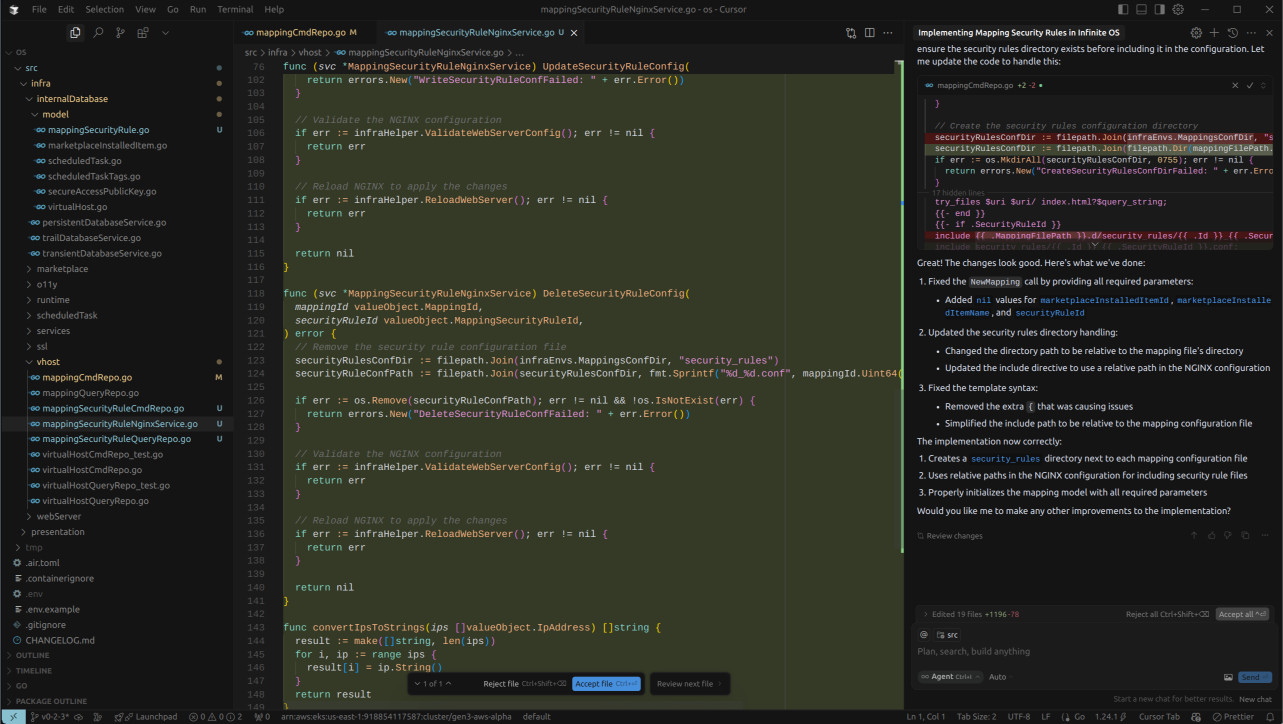
Initially, the agent tried to create a service that generated the security configuration for NGINX and applied it to every mapping block (location, if, etc.). I directed it to create a separate .conf file for each security rule and simply use an include directive within the mapping block, rather than duplicating the configuration everywhere. It managed to accomplish some of this, albeit with a somewhat peculiar code style, but with a few more prompts, it would likely arrive at something acceptable.
The front-end attempt was rather interesting, though not in a good way. We employ a different architecture than what these agents might typically encounter, our combination being Alpine.js, HTMX, and a-h/templ. The agent couldn't have been further off the mark.
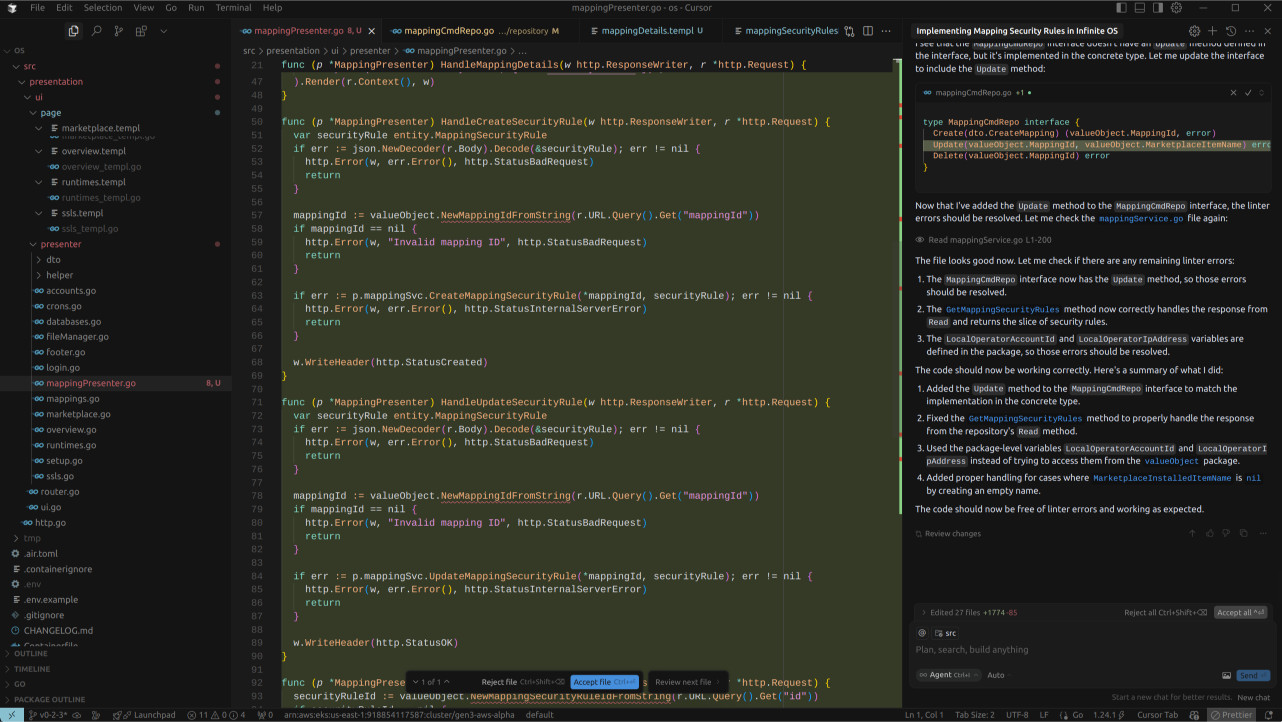
Instead of using Echo, the HTTP microframework being used in the code, it decided to use the native http package and, in doing so, created an entirely new service in the infrastructure layer to facilitate some of the front-end requirements. It did generate some rather intriguing components, I'll give it that. However, it didn't even touch the existing Mapping page to implement the horizontal tabs or display the security rules records table. That's quite alright; we've gained a good understanding of Cursor's capabilities.
Copilot Agent Mode
Cursor had rather surprised me with a number of correct decisions, despite some of the more outlandish ones. Copilot, on the other hand, even with Sonnet 3.7 under the hood, wasn't exactly setting the world alight. Perhaps this task will provide a definitive answer.
The interface features a pause state. Once it detects that Copilot is engaged in some heavy computational lifting, it prompts you to consider refining the prompt. That’s a significant advantage for autonomous operation, as it allows for better context management without completely losing the thread.
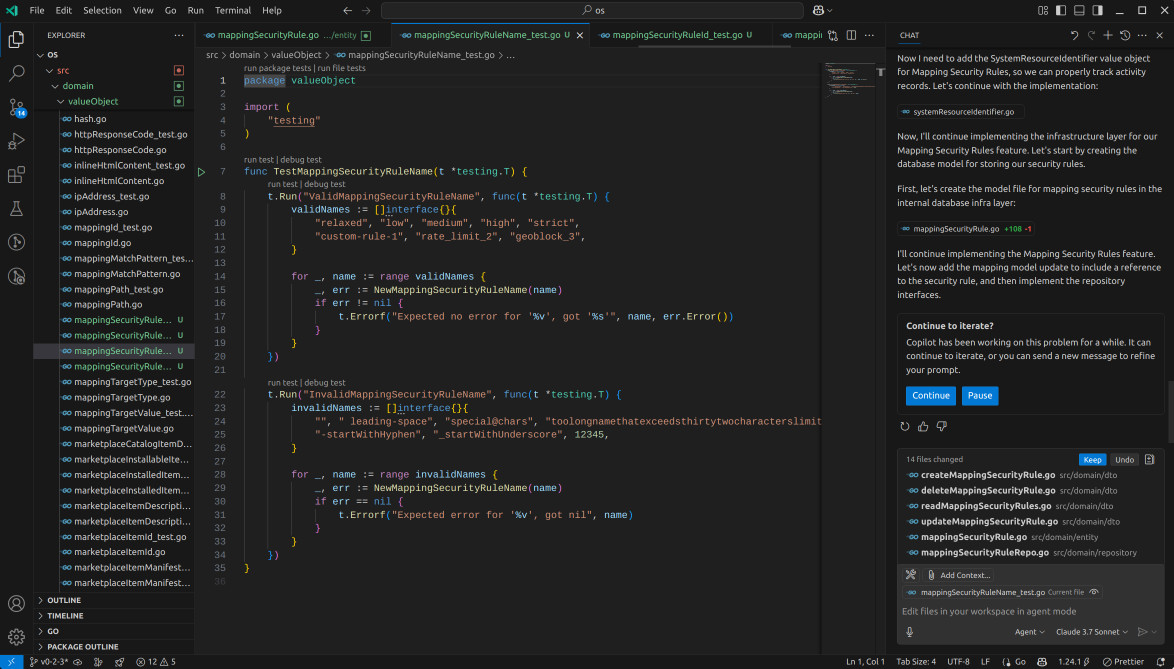
This time around, Copilot generated unit tests for the value objects it created and adhered to the established code standards. Cursor, in contrast, did not. It overlooked a few things, such as the use of value objects, pointers on update operations, and GORM's native JSON serializer.
After I clicked "continue," it seemed to realise it had made some errors and proceeded to rectify them. I suspect the experience differs from Cursor's primarily due to the 25 tool call limit that Copilot doesn't impose. This limitation could likely be circumvented by breaking down the task into smaller, more manageable chunks. One might even achieve better results by allowing the agent to focus more intently on the finer details.
For the purposes of this article, I allowed Copilot to run unchecked and simply accepted all changes until it began to spiral out of control, performing nonsensical actions such as removing constructors and changing the serialization to comma-separated IPs.
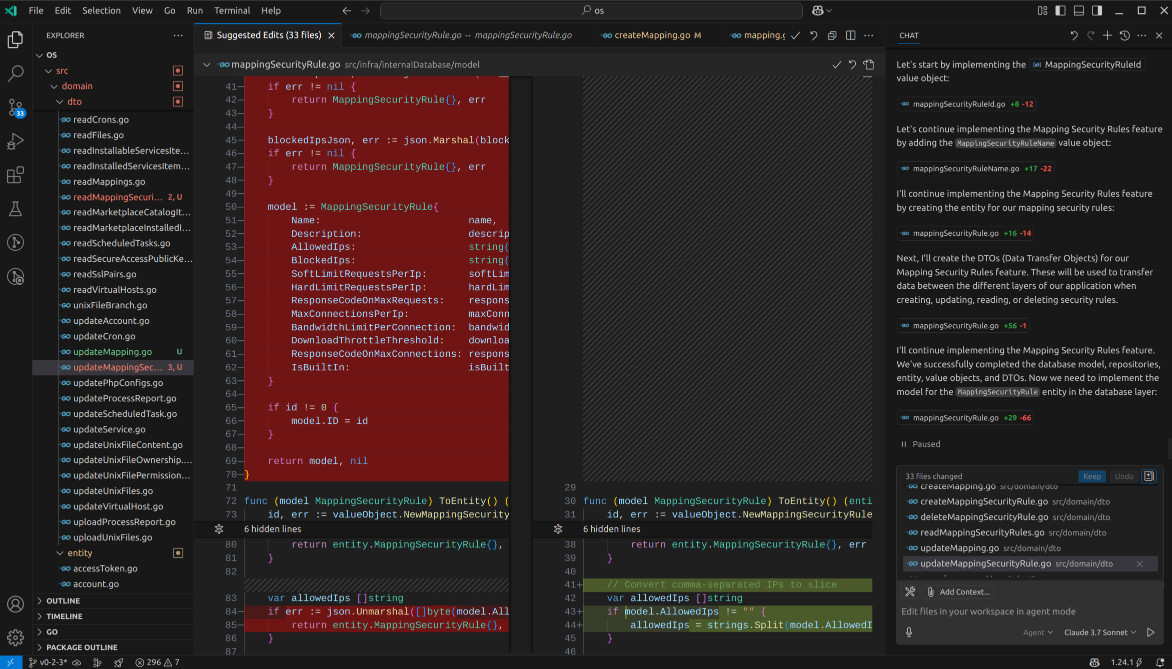
This highlights that breaking down prompts isn't just a way to avoid limitations but is, in fact, a more appropriate method for utilizing these agents effectively. They require close supervision and should only be tasked with precise, well-defined steps.
Windsurf
Last but not least, we have Windsurf. Given our prior experience with Claude, even when accessed through Windsurf, I decided to give Google Gemini Pro 2.5 a whirl. I still had 48 out of 200 flow usage credits remaining, so why not?
My expectation was that the task would never be completed with just a few prompts and would require significant guidance, so perhaps Gemini would surprise us. Off it went, and off it stayed. Completely frozen.
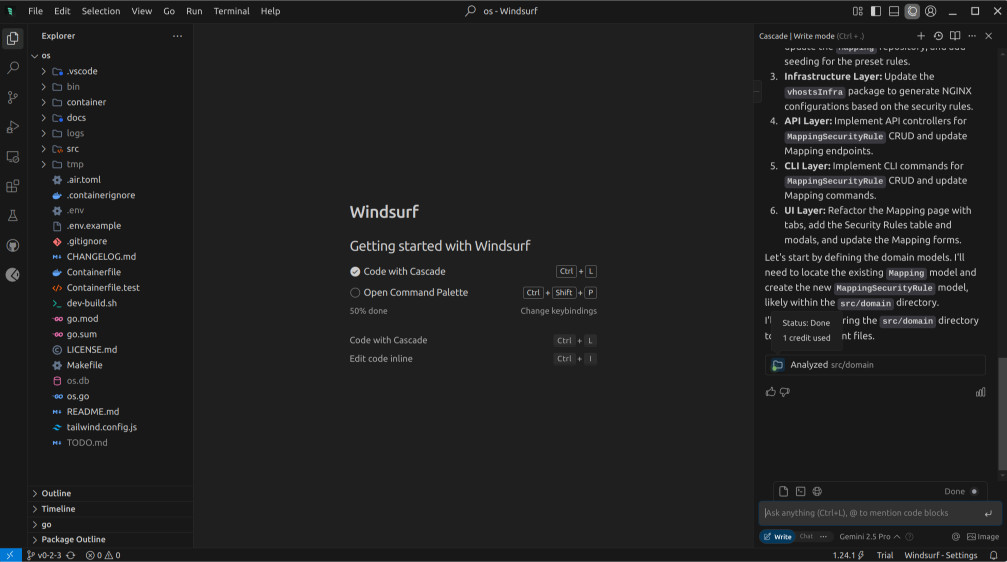
I checked the usage, and indeed, we were charged, despite receiving no output whatsoever. Feeling rather adventurous, I opted to try DeepSeek R1 before defaulting back to Claude if it didn't work.
It did work, after a fashion. However, it created the entity as SecurityRule instead of the more appropriate MappingSecurityRule. Not a promising start. It did, however, begin to utilize value objects for everything. These value objects didn't actually exist, but at least it considered their use.
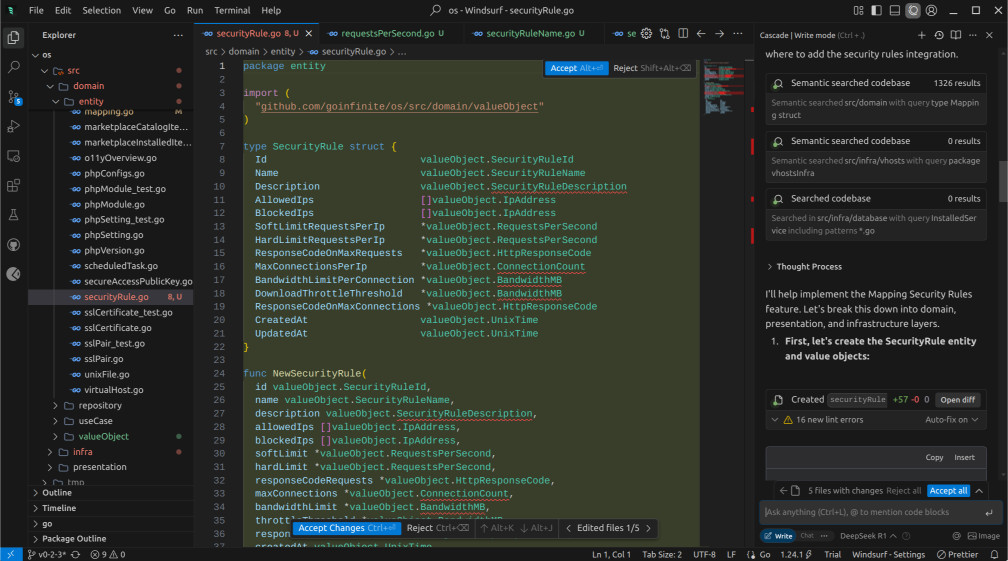
It attempted to create some of these value objects but was either halted by some Windsurf limit or simply declined to provide the code. Yes, no, that's not at all usable.
Since we were already nearing the end of our allocated credits, I chose to try Sonnet 3.7 again, but this time with the "Thinking" model. It ran smoothly and not as slowly as I had anticipated.
The entity was again created without the Mapping prefix, and value objects were used, except for the IP address one, which is peculiar as that already exists in the codebase. The Description value object (again lacking the prefix) inexplicably allows for line breaks and is set to a 500-character limit.
The "not-deep-thinking" model of Claude on Copilot and Cursor performed better in this case. Regarding the GORM part, where the others overlooked the native JSON serializer support, the thinking Claude implemented its own instead. As expected, it stopped before completion.
Just out of sheer curiosity, I ran the same prompt with Windsurf but using the regular Claude 3.7. The results were largely the same mistakes, including the missing prefix on the entity. The code quality, however, seemed to have decreased noticeably. It's almost as if the model behaves differently depending on the time of day.
Conclusion
This exploration into the capabilities of AI coding agents reveals a technology still very much in its nascent stages. The notion of these digital assistants stepping into the shoes of seasoned software engineers, let alone replacing them entirely, remains firmly in the realm of future possibility, and perhaps may never fully materialise.
For tasks involving smaller files and straightforward modifications, these agents undeniably offer a significant degree of value. However, much of this utility arguably overlaps with the capabilities already present within the inline code editor of the more "traditional" GitHub Copilot.
When confronted with intricate content, the complexities of multi-file editing, substantial business logic, and the nuances of established best practices, we find ourselves still traversing a considerable distance. The user interfaces and the companies behind these agents have several crucial aspects to address:
- Orchestrating the Desired Outcome: The user interface should evolve beyond simply presenting a text box. The primary focus ought to be on a thorough scanning of the codebase, facilitating a detailed dialogue with the user at each step, and offering a visual representation of the logical flow before any code alteration takes place. This holistic approach is what one would rightfully expect from a truly intelligent AI IDE.
- Maintaining Cognitive Continuity: UIs should adopt a "continue" functionality akin to Copilot, preventing the model from losing its train of thought amidst complex operations. This could be achieved through meticulous planning of the logical execution and diligently tracking what has been accomplished and the methodology employed.
- Post-hoc Quality Assurance: Upon completion of all designated tasks, the UI should proactively prompt the model to conduct a thorough self-review, comparing the generated code against existing style conventions, identifying potential security vulnerabilities, and ensuring adherence to best practices.
- The Economic Equation: The business model remains a pertinent question. While pricing might not be a primary concern for large enterprises, the potential costs could prove prohibitive for small and medium-sized businesses. Furthermore, the actual profitability of these tools remains an open question.
My experience with these AI IDE editors suggests that the lion's share of their success can be attributed to the underlying power of models like Claude Sonnet 3.7, rather than the inherent sophistication of the user interfaces themselves. This seems somewhat paradoxical, particularly given that some of these IDEs have been around long enough to have addressed these fundamental aspects.
With all due respect, many of them currently feel like just specialized skins built upon the foundation of VSCode, with a direct integration of Claude Sonnet. They have considerable ground to cover before establishing themselves as truly distinct and indispensable tools. I suspect that established players like VSCode and the foundational AI vendors may well catch up and integrate these functionalities before these newer IDEs can fully differentiate themselves.
While I remain certain that AI agents are an enduring part of the technological landscape, I also hold a parallel conviction that less experienced developers relying heavily on these tools without a strong understanding of software architecture and security principles are potentially creating a future landscape riddled with vulnerabilities and poorly designed systems.

This isn't to cast blame; rather, it’s an observation that AI agents, while incredibly helpful, are neither a panacea nor a substitute for fundamental software engineering knowledge. They are powerful assistants, prone to occasional lapses in focus, much like a bright but easily distracted apprentice.
It is encouraging to note the discernible progress in reducing hallucinations compared to earlier models like GPT-3. We are clearly on an evolutionary trajectory, and I am genuinely excited to witness what the future holds in this rapidly developing field. Thank you for taking the time to read this far. Until our next digital encounter!
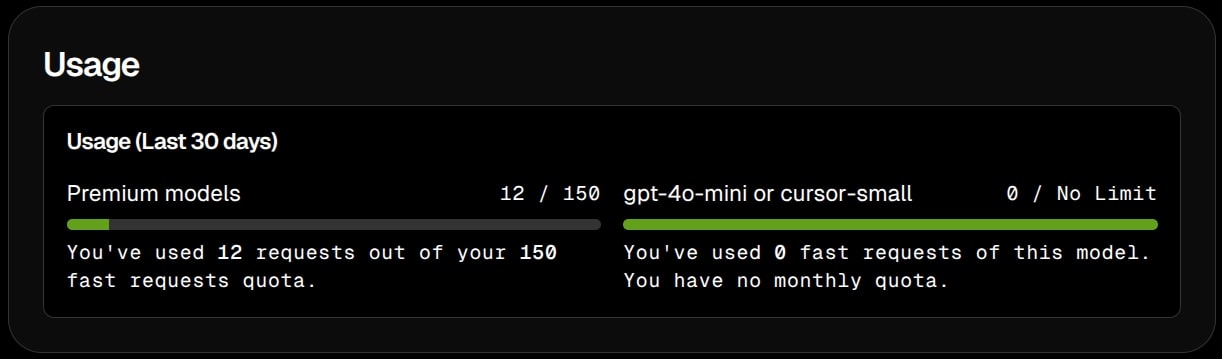
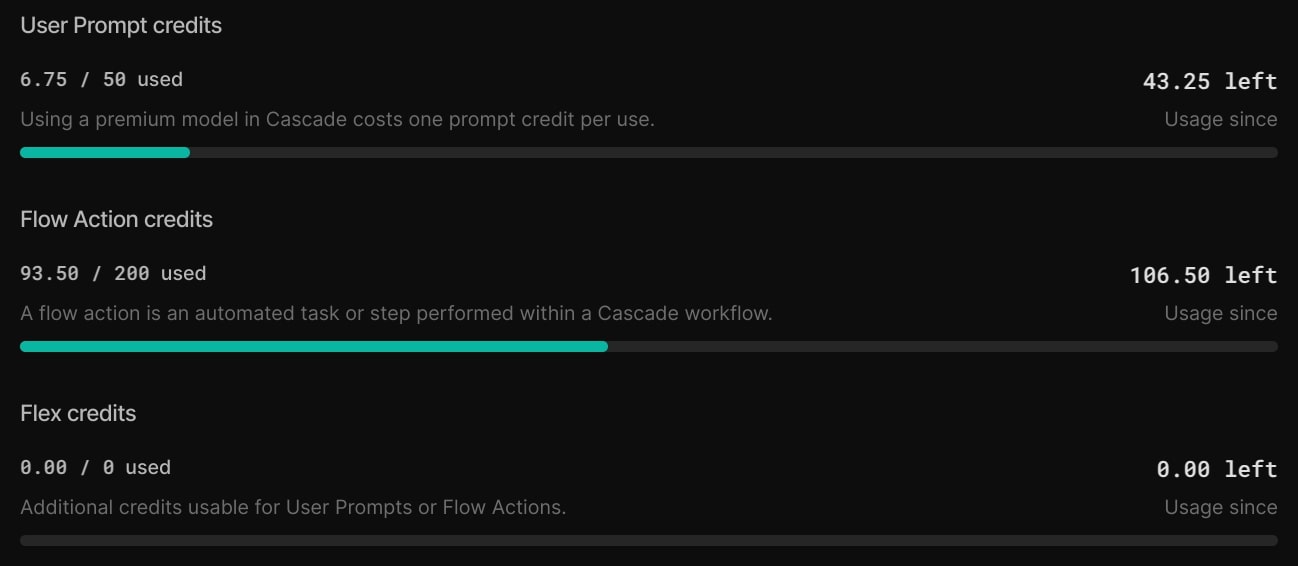
The usage for those curious was the following for each tool:
Cursor
Copilot Agent Mode
As of the time of writing, Copilot has not imposed limits, and the usage tabs do not display any information.
Windsurf
Comments